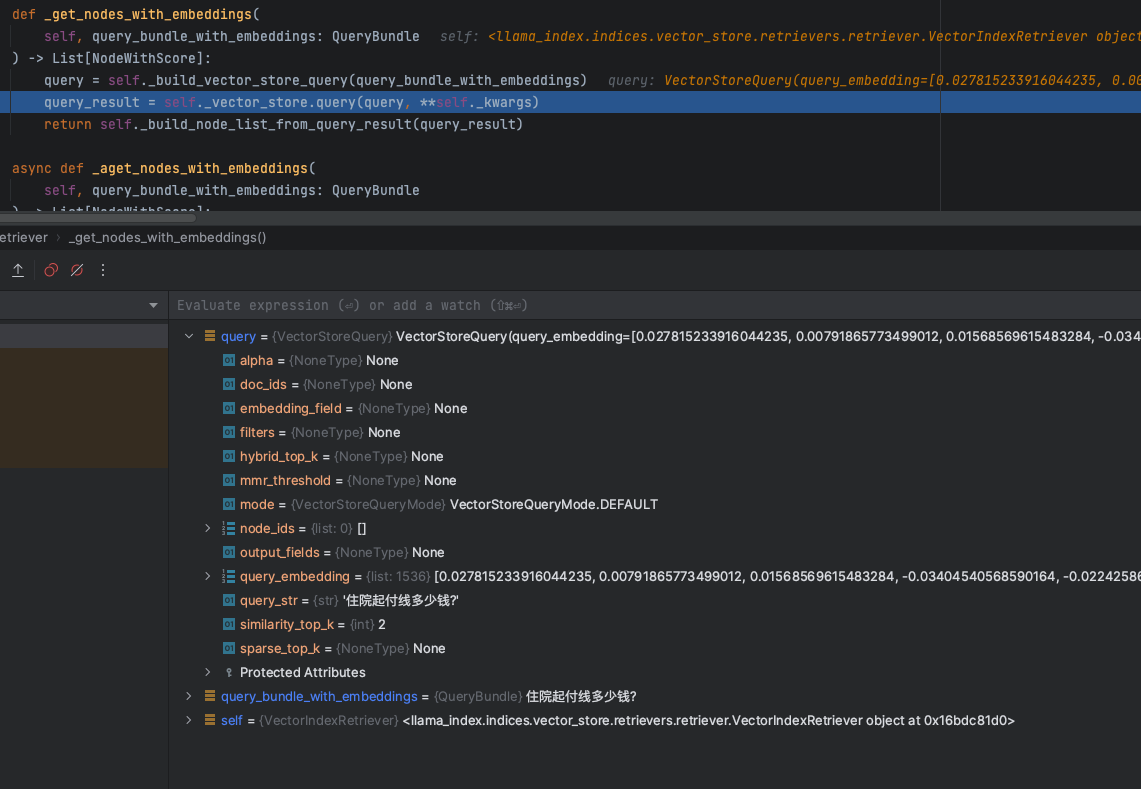
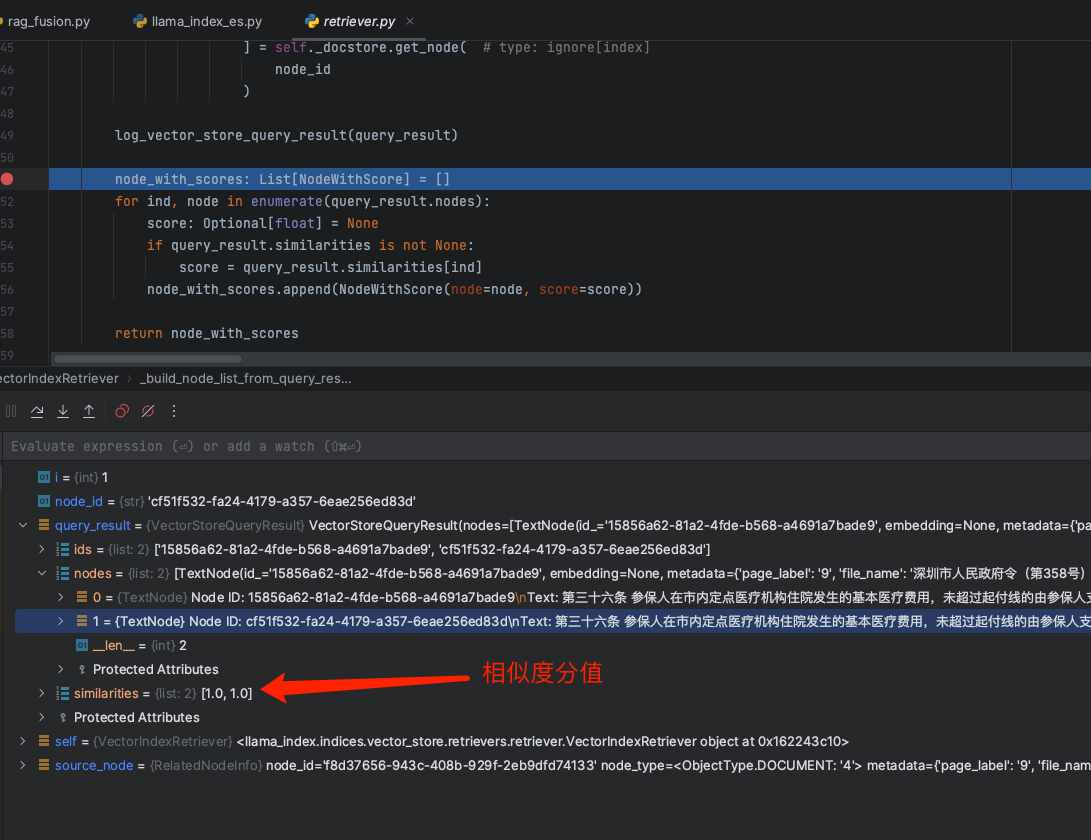
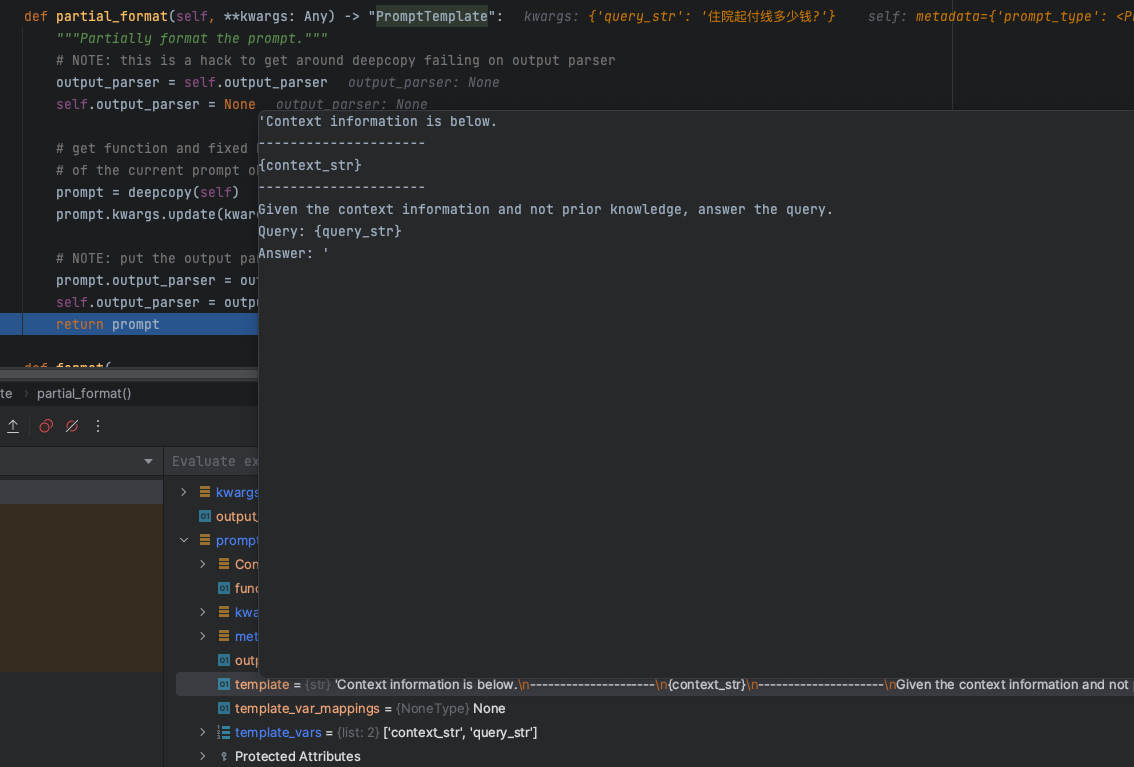
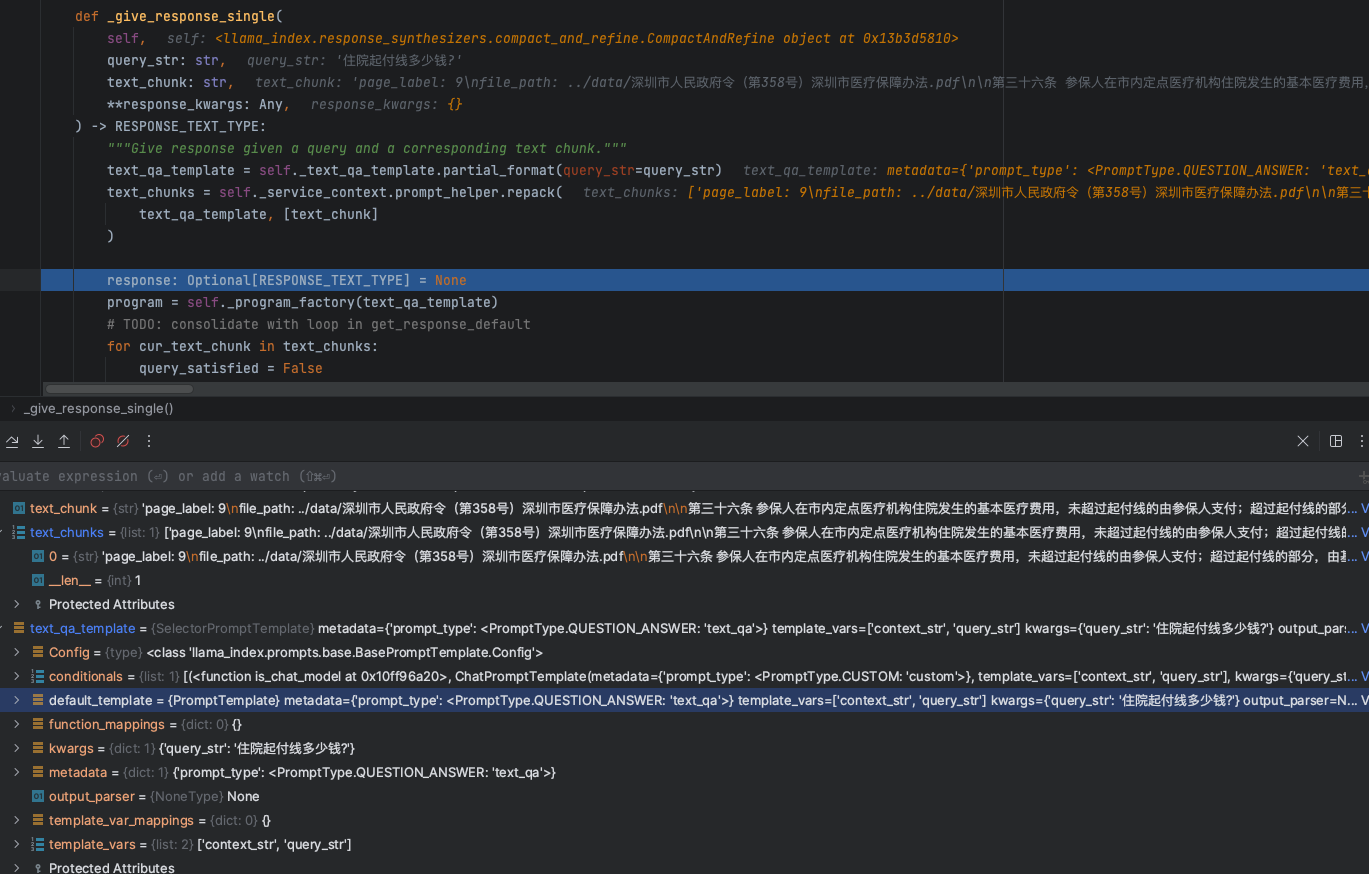
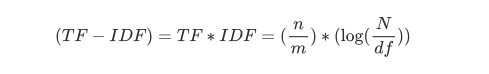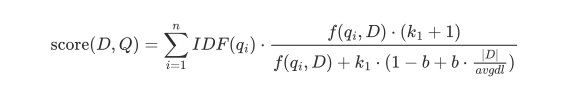以下内容是8.15日我在上海张江科学会堂举办的“GOTC(全球开源技术峰会)” 与 “GOGC(全球开源极客嘉年华)” 分享内容文字稿,分享给大家。
一、前言
大家下午好,
我叫肖玉民,来自杭州萌嘉网络科技有限公司,很荣幸受主办方的邀请,来参加此次GOTC2024的分享。
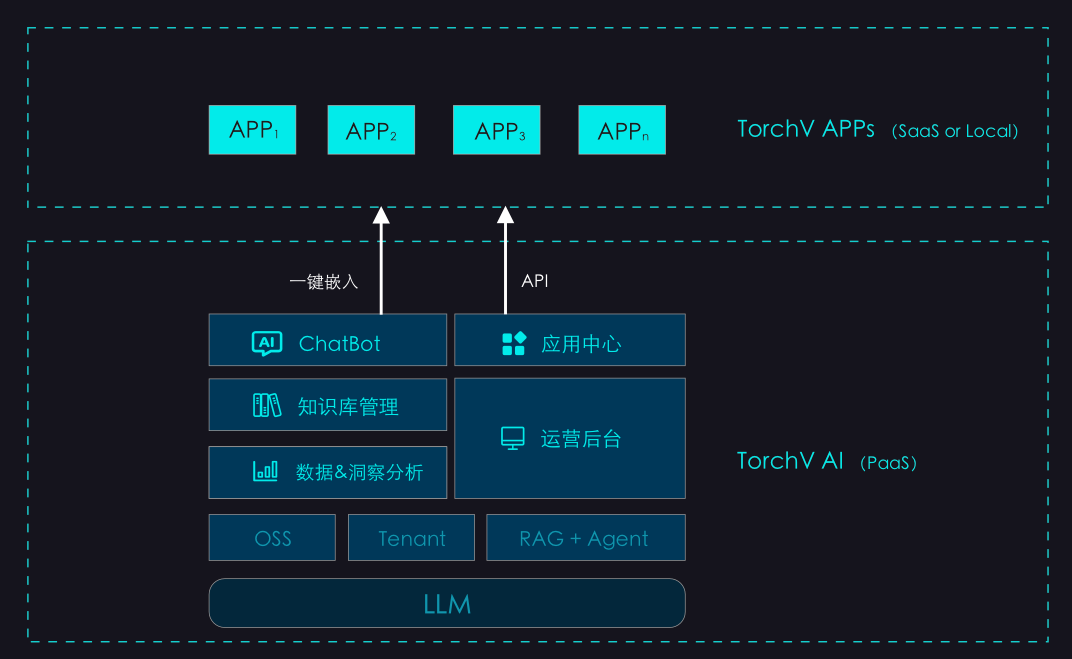
我们是一家刚成立不久的初创公司,目前主要聚焦在大模型、向量检索、RAG这一块的产品应用研发,我们的产品品牌是TorchV。
今天也是借着这个机会,结合我们自己做RAG产品迭代开发过程中的一些实践,分享我们在非结构化数据解析以及企业应用场景的一些探索和思考。
OK,今天我分享的主题主要围绕三个方面
- 第一是非结构化的数据处理,做RAG的产品迭代基本是从非结构化数据解析开始。那么这一节会围绕整个技术中间件的选型,包括PDF的表格解析等内容进行展开
- 第二部分是,企业AI场景落地,我们的产品应用探索和思考
- 第三部分是总结和我个人的一些感想。
二、非结构化数据的解析难点&细节
OK,那么说到非结构化数据,自从RAG+大模型的技术栈爆火之后,我们看到了大模型在处理文本上的能力,为止惊讶。
在我们的实际应用场景中,可能80%的工作场景,都是在和非结构化打交道,这其中包含场景的Office办公软件套,还有图片、音频等等各种各样的结构数据。正式因为有了大模型的能力,让非结构化数据的内容,在整个内容检索、理解、利用等方面得以充分的发挥。提供人们的工作效率。
我们以RAG为基础的技术栈进行技术开发时,开发人员碰到的第一个难题也是以非结构化的数据解析为起点,我们需要将各种各样的格式的数据解析成文本,然后在通过检索、写Prompt的方式,让大模型进行推理生成,完成上游的应用部分的交互,解决人们在工作中碰到的各种企业问题。这里面我们碰到的问题:
- 文件种类繁多,非常广泛。
- 老旧文件的支持问题,比如DOC、XLS、PPT等格式的支持
- 表格解析是难点
- OCR的启动时机,从成本、效率、性能等多方面去考虑
- 布局识别在PDF中的能力有待突破
- 文件的字符编码问题等等。
在实际的开发场景中,可能还有很多的细节,需要开发人员去处理。
在碰到上面这些问题时,一开始我其实也有点不知所措,就拿PDF的格式来说,其1.7的规范就将近800页,如果要全部看完并提取解析成功。那可能是天方夜谭了。
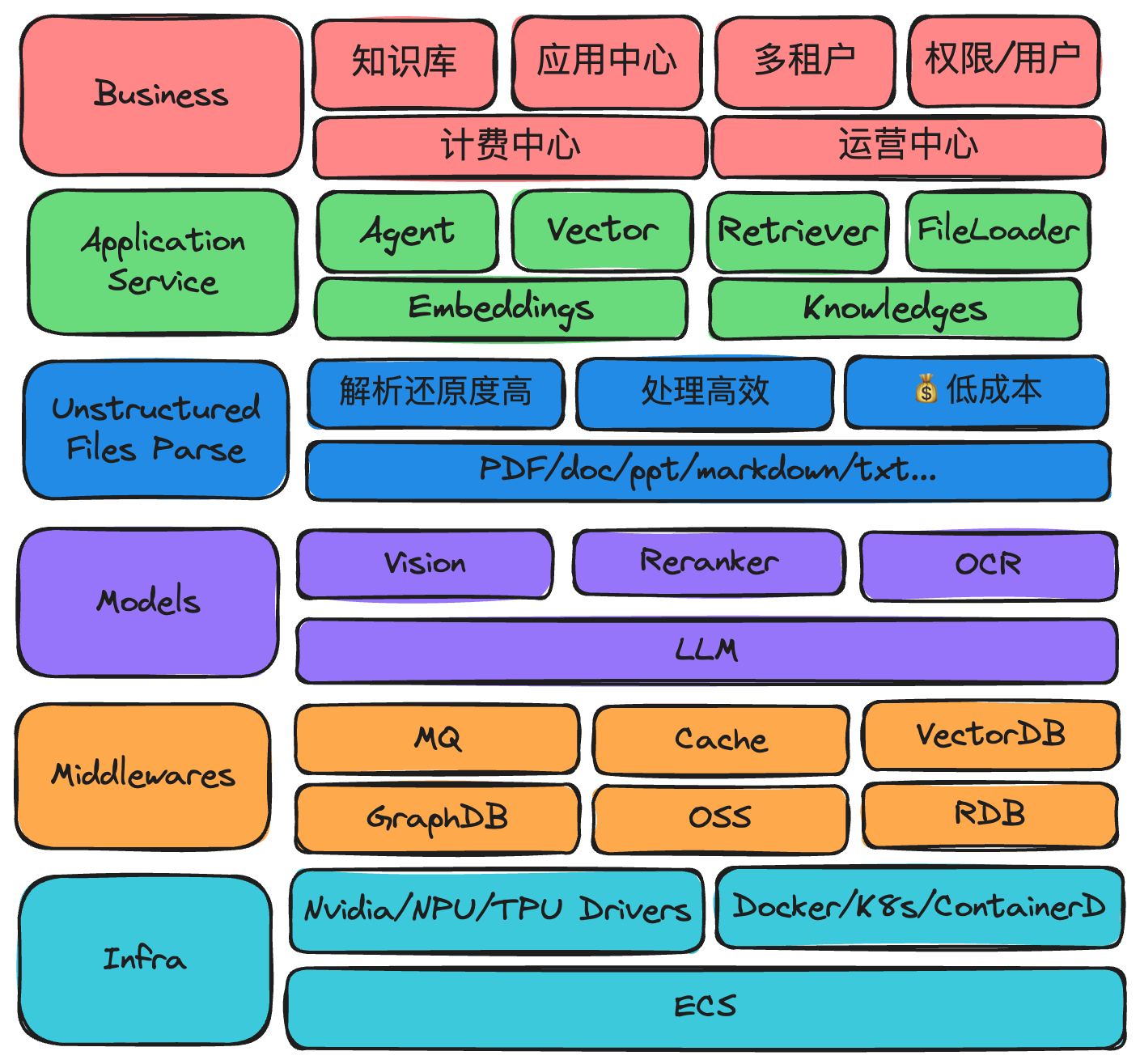
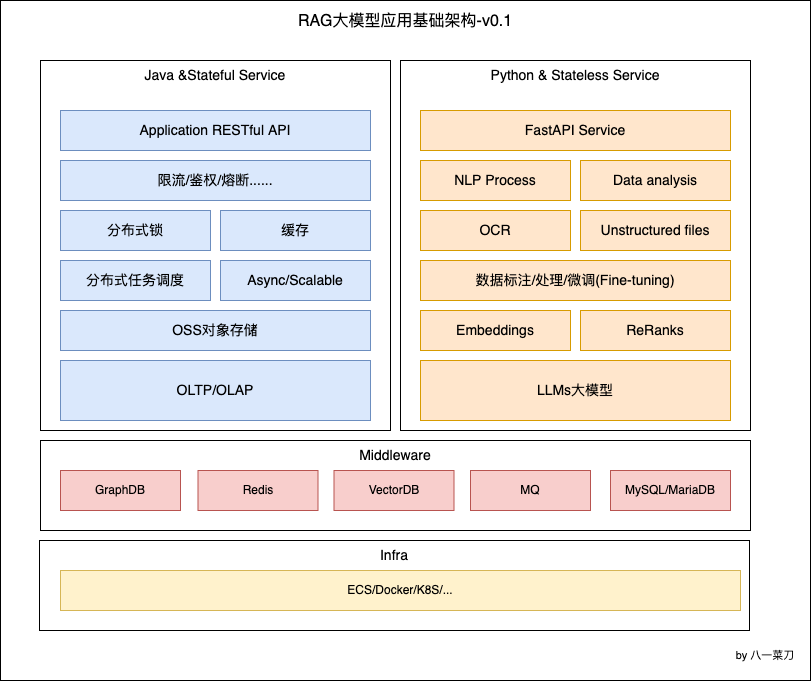
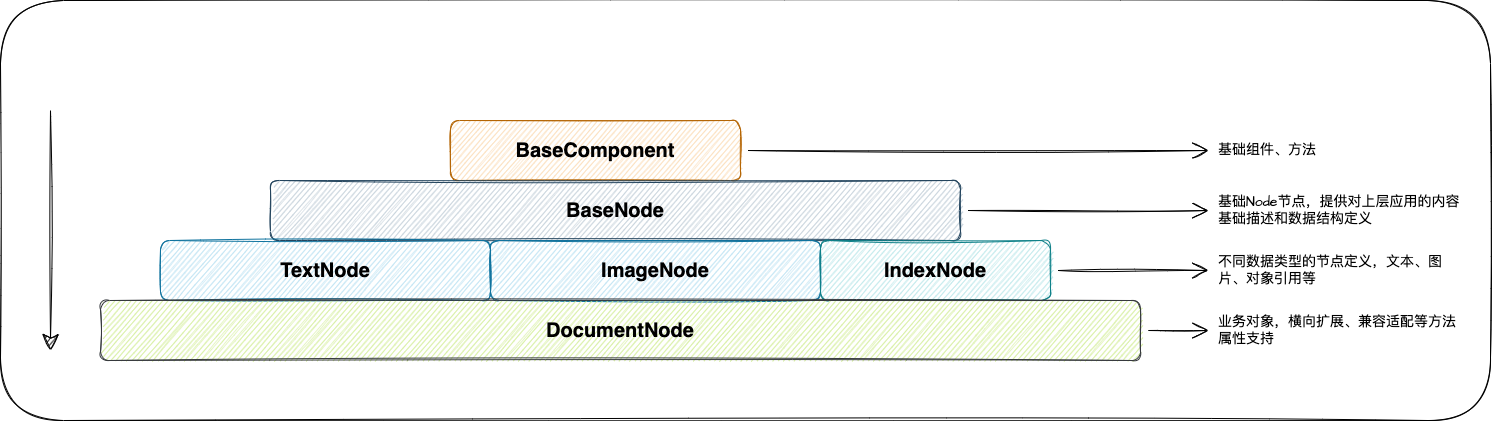
我们可能和其他的开源的产品或者同类的产品不太一样的是,在TorchV的整个技术架构体系中,Java占的比重有将近80%,当然这里面包含文件的解析内容提取。

在Java生态中,针对上面的一些文件解析的问题,在目前整个Java生态里面,有三个中间件是很很好的在做RAG场景中,发挥重要作用的。Apache三件套。
- Apache POI:第一个是POI项目,早在02年就进入了Apache基金会,早期是主要处理Excel的电子表格为主,后来支撑了包括word、ppt、visio等多种格式的支持。poi项目在以Java项目为主导的AI应用开发中有一个主要的优势技术对老文件的支持,像DOC、XLS、PPT等格式的文件,POI可以完全不依赖外部插件或者中间件的情况下直接解析,提取文本内容。这相较于Python生态提取Office套件的文件格式还是蛮有优势的一个点,Python的生态,以docx解析为例,大部分的解决办法都是先将doc转换为docx,然后再进行提取处理。这需要依赖外部插件。这点Java依靠多年的技术沉淀,还是蛮有优势的。而且我们在很多大客户对接过程中,发现老文件占比还是蛮重的。
- Apache Tika:Tika是一个比较综合的文件解析项目,起初是作为Apache Nutch项目的一部分,在07年独立发展成为顶级项目,Tika在文件解析领域做了很多的封装,其涵盖了POI、PDFBOX这些项目的应用依赖,能够通过识别文件的魔法值,自动甄别文件类型,提供标准的输入流及转换扩张方法,这里面也集成了OCR的识别,在解析文件过程中,对于图片资源也启用OCR进行提取。
- Apache PDFBOX: PDFBOX是目前开源领域中,非常完善&成熟的一个PDF文件处理中间件了,发展历史悠久,08年进入Apache基金会,PDFBOX较完善的提供了对PDF规范的支持,并且提供了顶级的抽象接口,供开发人员进行自定义扩展,非常的方便。
在整个的非结构化数据提取过程中,上面这三个Apache项目,基本能解决我们80%的业务场景的问题,我知道目前大家对于大模型来提取识别文件觉得是非常酷的一件事件,但是在企业场景落地的时候,文件解析我们也是需要从成本、性能、效率等多方面去考虑。
有时候基于规则的提取,在可解释性上还是有较大的优势的。
我们基于上面三个中间件,其提供的文件格式大家也可以看到从Html、Office、PDf、图片、音频、压缩包等等,在企业应用场景中,绝对够用。

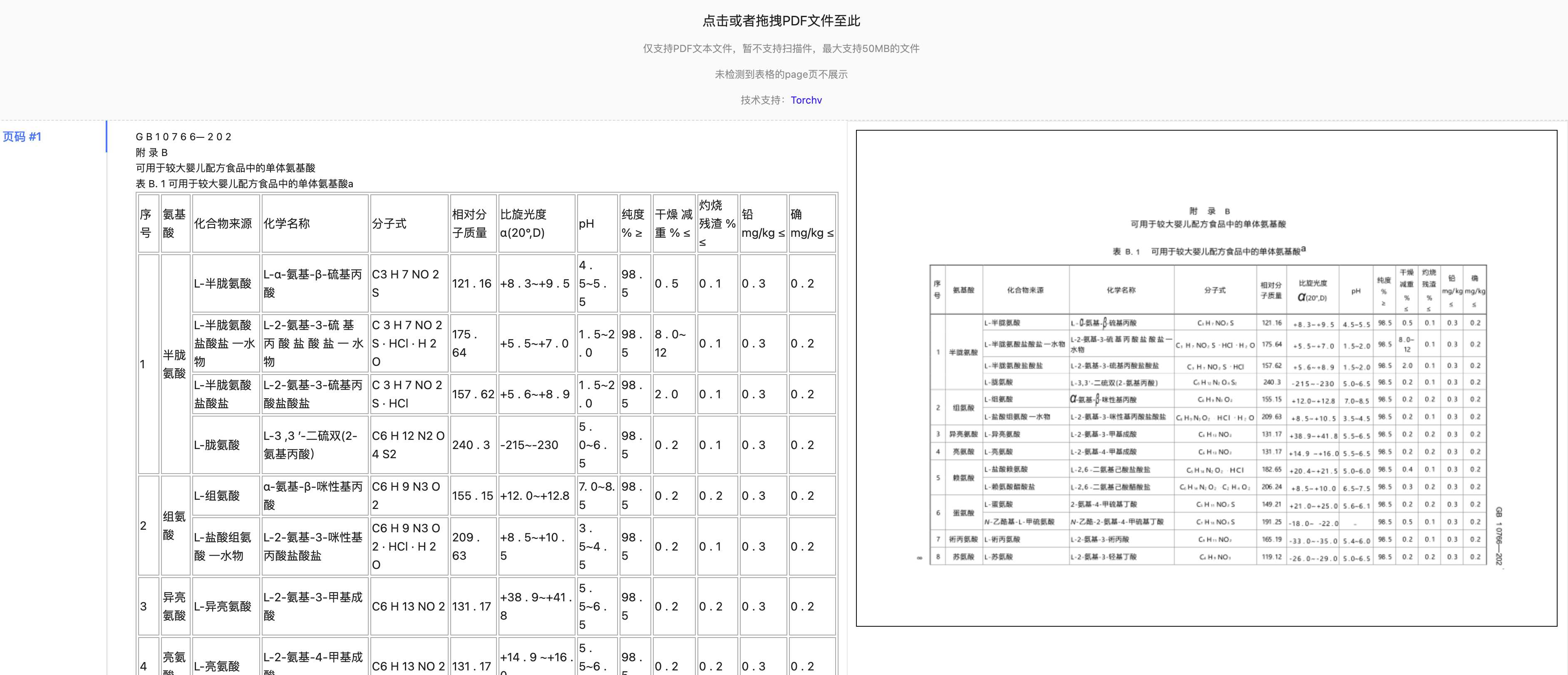
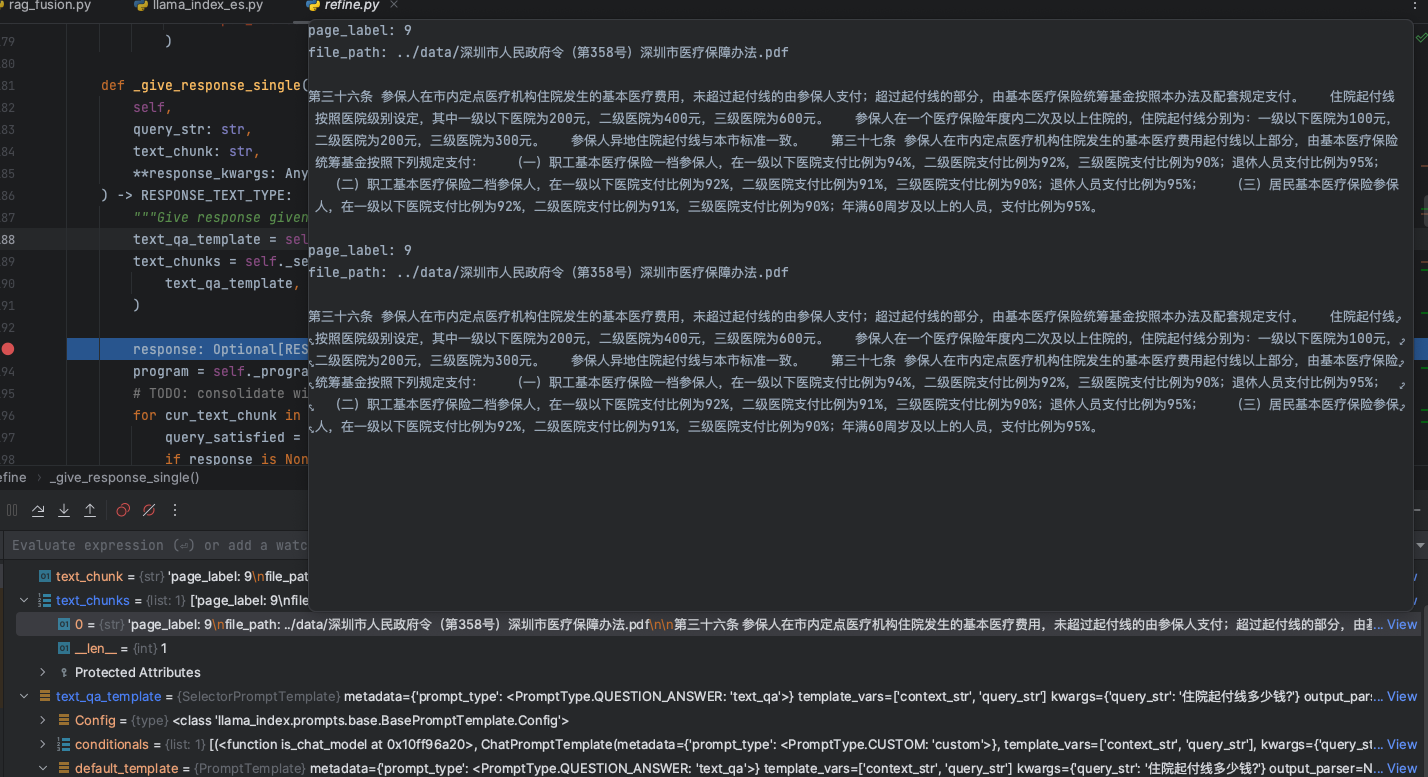
在整个文件解析中,PDF应该是最令开发者头疼的一个文件格式,尤以表格提取最麻烦。
在PDF的表格提取中,借助于Apache PDFBOX,目前有两种有效方法,是可以非常高效的提取表格内容,还原表格信息。

第一种是Tabula组件,开源的算法,主要基于PDFBox提供的文本坐标提取方式,通过将所有的文本坐标提取后,通过计算边界、文字边界连接等方式,可以通过坐标算法,基于水平和垂直两个方向的坐标系来明确单元格的边界,将整个表格还原提取出来。
这种方式在针对一些老的电子文件PDF是非常奏效的,因为在之前的PDF标准规范中,对于表格中的线、矩阵等信息并没有纳入规范中。而在目前的PDF规范中,PDF对于电子文件的内容流中,大部分场景都存储了表格中的线、矩阵坐标信息。
基于这个方式,我们可以使用PDFBOX中的第二个方式来还原提取PDF的表格信息,这主要是通过提取PDF内容流的线坐标、矩阵信息。
可以通过将所有的矩形、线的坐标信息,通过算法进行处理,这里面包括空间去重、冗余排除、矩阵坐标连接等方式,那么就可以做到图中的这样,将一个表格信息完整的画出来,我们通过矩阵坐标确定表格后,基于表格的单元格坐标,即可以进一步的确定当前表格他的单元格合并情况,明确每一个单元格是否需要纵向、横向的合并。最后确定这些信息后,通过PDFBOX按区域提取的方式,就可以精准的提取每一个单元的内容信息,将表格幂等的还原回来。
另外基于坐标的信息,其实要扩展做的内容也蛮多,在后面的案例我会讲到。
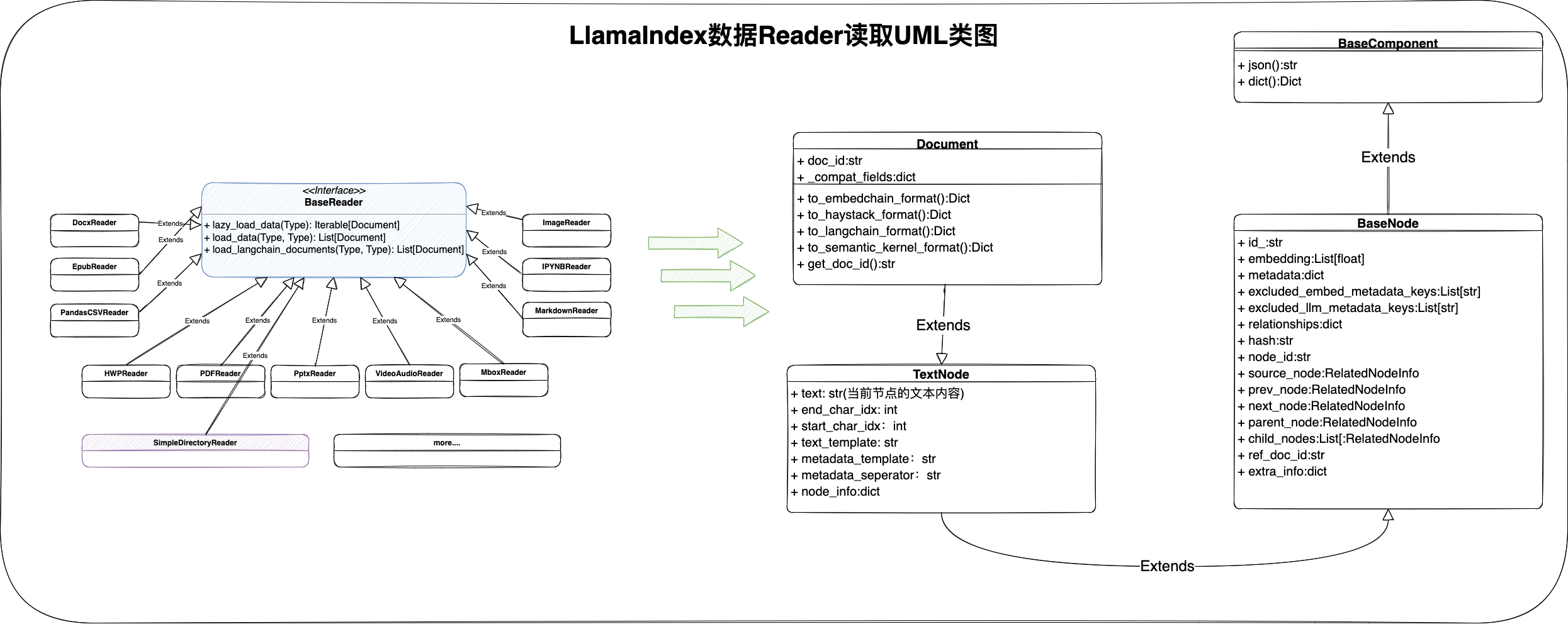
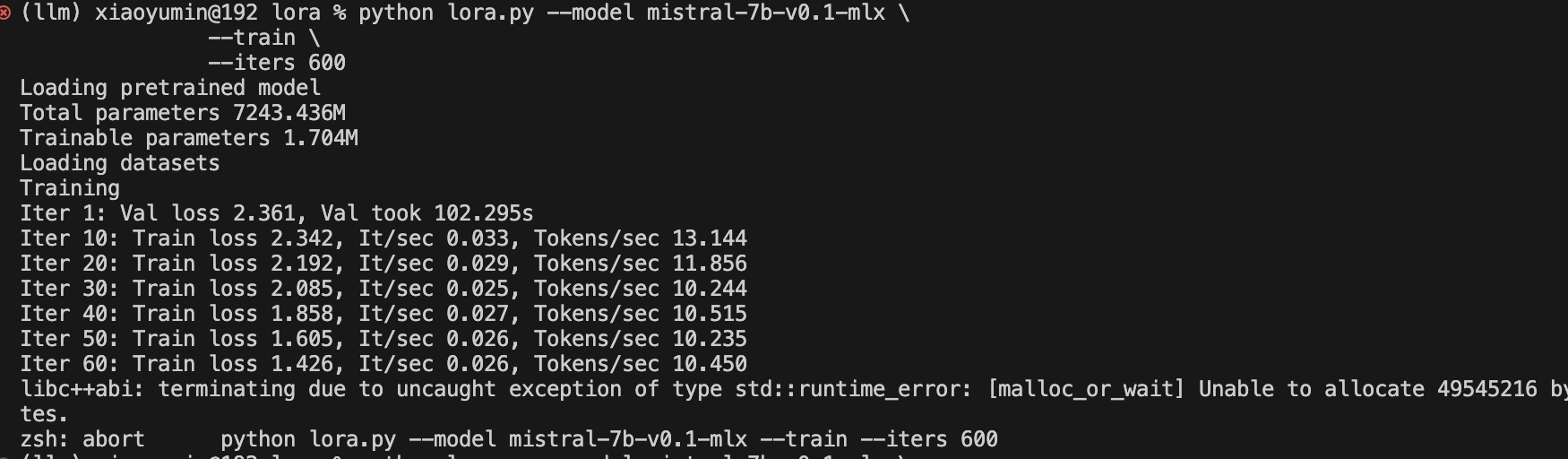
基于上面表格的提取方式,在PDFBox中,他的整个UML架构图就如图中所示:
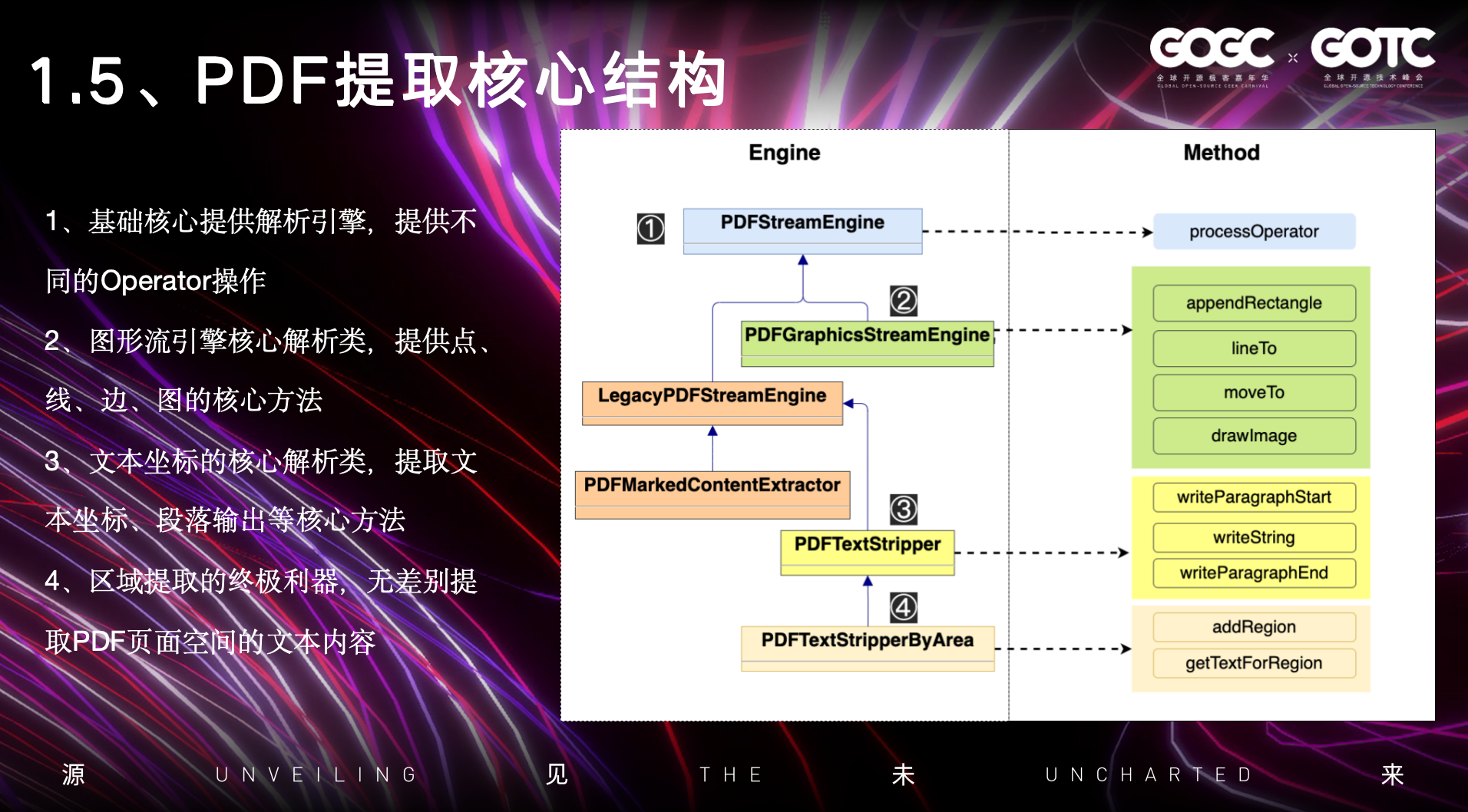
最顶部是PDF基础的引擎类,在PDF的规范中,包含了非常多的Operator操作,下面的基于坐标、图片等信息的提取,都是基于PDF规范中的Operator来扩展提取。包括第二个图引擎的类,实现提取内容流中的线、矩阵、图片等信息的提取
最后按文本坐标区域提取的核心类,是一个非常实用的方法,在PDFBox中,特别是对于当前论文类型的PDF,双排的这种方式,通过大量的实验,其实提取计算文本的排版空间,都是比较轻松的一种方式。
三、应用探索 & 实践
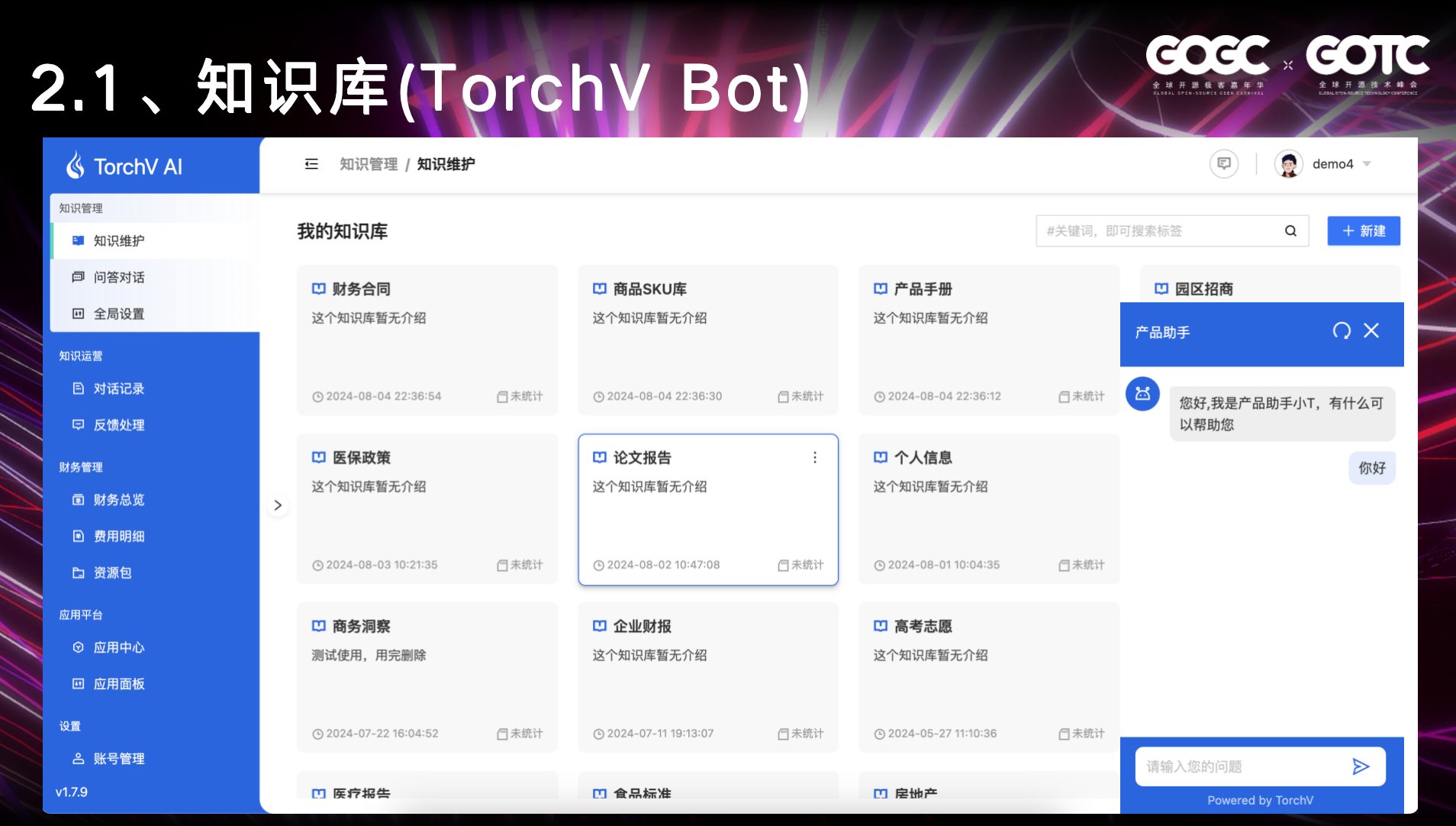
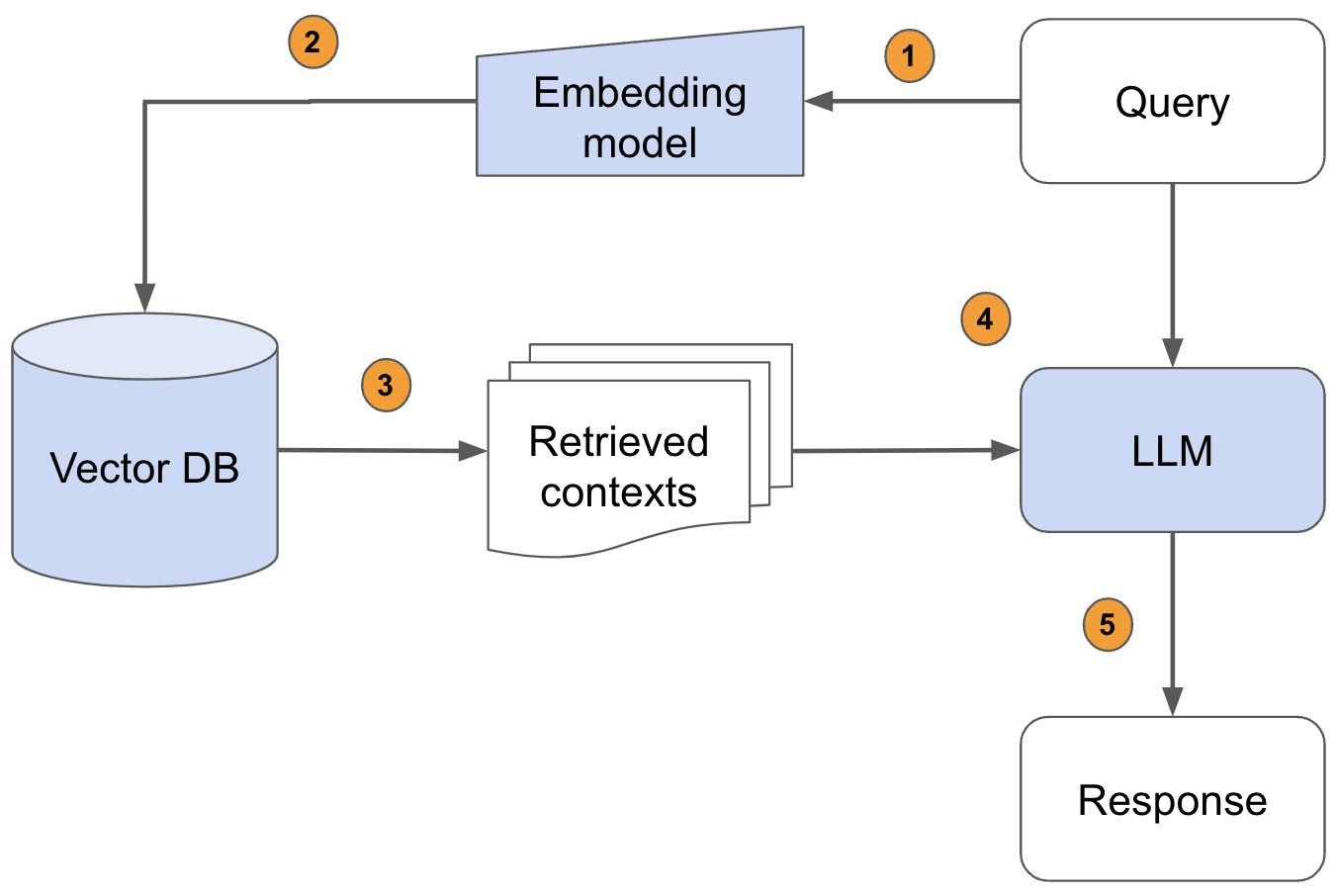
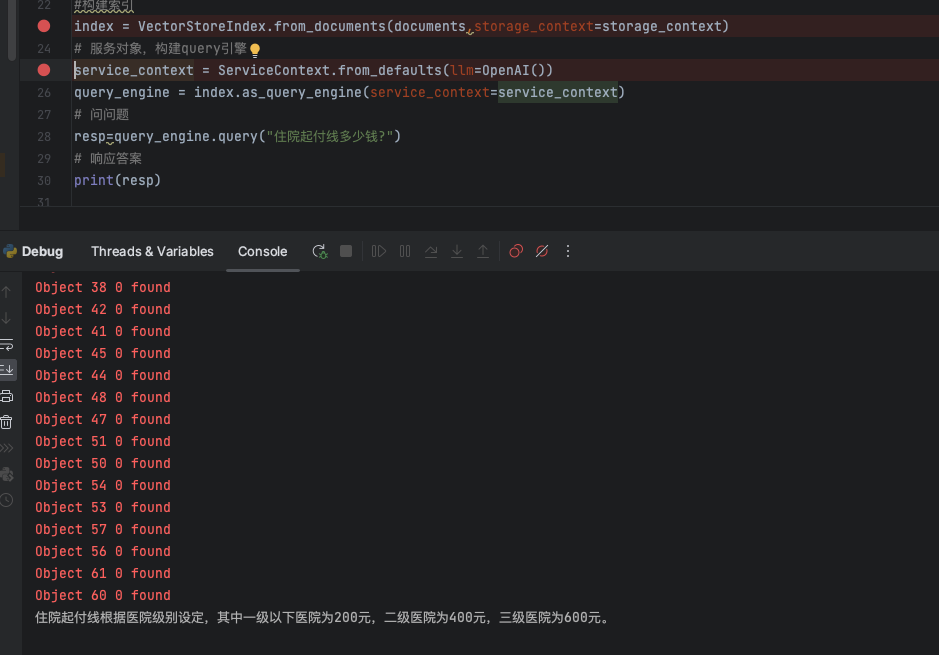
第一个场景是知识库,这也是基本在大模型兴起后,最常见/可落地的一个领域,今天因为大模型超强的文本理解能力,我们通过各种手段将非结构化数据进行文本提取解析后,结合向量KNN等新一代的搜索技术,可以更加准确的搜索积累在数据库中的文本内容。
配合大模型作为润滑剂,将整个用户的问题进行理解,最后输出符合用户问题的答案。
我们在和我们的客户深入沟通交流的过程中,知识库就像AI时代的数据中台一样,做好知识库能给很多企业充分将AI的能力利用起来。
这里面包括:
- 企业内部的非结构化的数据、知识统一管理。
- 通过PC、Web等不同的方式,对于企业内部的知识在整个组织上如何更好的协同、分享。
- 让知识更高效的利用,把冷冰冰的数据从数据库里面捞起来,发挥数据的再利用的价值。
这个是我们认为当前AI在企业场景里面非常重要的一个落地场景。
第二个场景应用我们叫研报助手Assistant.

他其实是一个富文本编辑器,大模型在今天其实已经非常擅长文本的生成了,对于知识的输出,效率相较以前数倍的能力提升。
但我们在企业的场景落地的过程中,大模型在一些严谨的场合下,输出的内容可能并不符合我们的要求,会产生幻觉,这也是RAG在当前最理想的一种技术手段,控制大模型的幻觉输出问题,让大模型基于给定的文本内容,进行总结输出。
Assistant主要是结合了非结构化的文本解析+向量检索+大模型归纳+富文本编辑器多种技术与一体的这么一个产品。通过用户上传的文档内进行检索生成,对于在一些需要引用严谨的报告输出,包括对大量文档的阅读,利用这个工具,可以高效的提升整个编写流程的体验。
在已经生成的文本内容,Assistant还加入了一些转换图表的能力,选中一些文本信息,可以快速的转换成饼图、柱状图、表格等不同的图表形式。
第三个是规则匹配的场景Cmparision
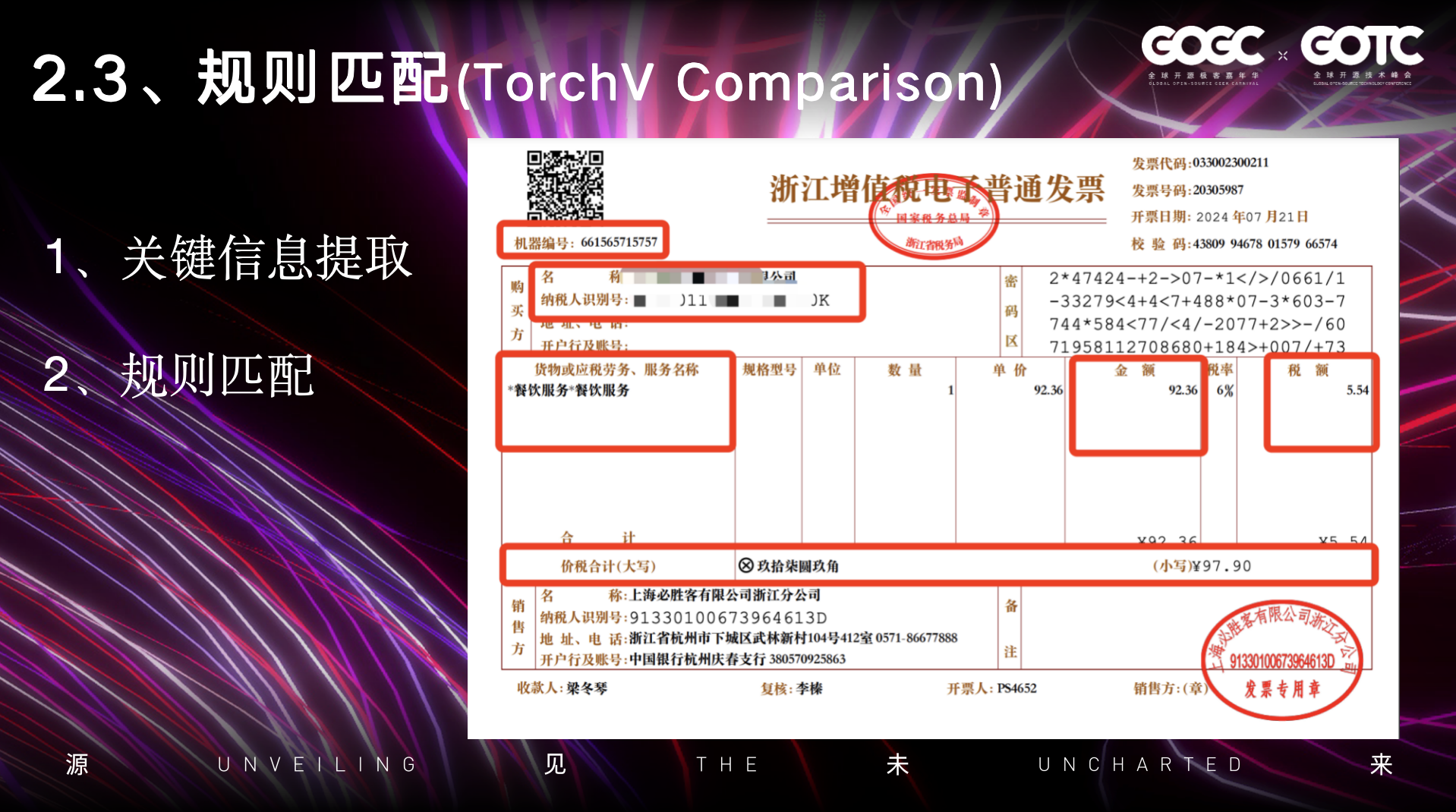
在这个场景中,我们主要还是依靠之前在处理PDF表格时提供的一些方法,可以无差别的根据区域信息,提取关键的字段信息。当然如果我们整个的处理场景中,会有一个处理的 顺序,如果PDF内容是扫描版本的话,那会通过OCR的方式,进行区域信息的提取,结合之前坐标空间的相关算法,将框定的内容给提取出来。
另外一个就是在非结构化的数据提取后,可以配合大模型的的Agent能力,针对特定的领域,基于规则提取文本中的关键信息。
提取关键信息后,那么我们在应用上层要处理时,不管是数据的校对、或者总结,在企业场景中,AI能高效的发挥作用,提供整体的工作效率。
四、个人感想
最后想和大家分享一下我的一些个人感想。
第一个就是:AI技术栈很杂,是挑战,也是机遇
在我们讲RAG、大模型、向量检索整体的技术栈进行落地时,这里面涉及到的技术栈其实是非常广,而且很杂,开发人员不仅仅要关注到数据的处理,这里面还包含检索、向量数据库、大模型Agent、Prompt、微调等等技术领域,对于打造一个标品其实并不容易。这对于企业和开发者来说,都有不小的挑战。但是正是有了AI大模型,我们在今天的工作场景中,很多有趣的应用和产品层出不穷,这里面其实也蕴藏了大量的机遇,同时在AI的加持下,对于开发者而言可以更加大胆的畅想了,这对于探索、创新,创造更多有趣的产品是大有裨益的。
第二个则是:数据质量是基石,重剑无锋
数据质量我觉得是在做文本类AI应用的基石,不管是做RAG,还是微调模型,我们在构建开发TorchV的过程中,可能大概80%的时间都是花在怎么把数据处理好,幂等的将非结构化的数据最大程度的进行提取和还原,这是很关键的一步,RAG更是有Garbage in,Garbage out的经典名言,所以,数据的质量,应该是我们需要着重关注的。
五、Reference
文中主要的中间件&信息:
]]>