大家好,这篇文章主要是介绍分享Knife4j-gateway网关聚合文档组件,自4.0版本发布该组件后,得到了大家的积极响应,我们也是积极响应用户的需求,持续迭代优化
该组件是一个非常轻量级的网关聚合组件,适用于开发者使用Spring Cloud Gateway网关组件进行Swagger2、OpenAPI3规范的文档聚合
🌾 1.前言
在考虑写这个组件之前,开发者在Spring Cloud Gateway网关组件下进行聚合Swagger2/OpenAPI3可能存在各种各样的问题
我认为主要包括:
- 适配不同的Spring Cloud Gateway版本,没有形成统一稳定的技术解决方案
- Gateway组件下Webflux异步编码的风格,学习成本异常陡峭,初学者一时之间难以掌握微服务体系
- 聚合文档代码强耦合业务代码,无法灵活配置
- 文档Ui无法随心所欲的配置
- 各种404或路径错误等问题
- 等等…..
🔥 2.解决方案
我们从开发者的实际需求出发,结合Knife4j多年开源以来积累的宝贵经验,决定了我们需要开发一个Gateway网关下的聚合组件
将开发者的需求、问题聚合在一起,众人拾薪火焰高,形成一个统一的技术解决方案
knife4j-gateway组件就是在这样的场景下诞生的
该组件主要的特点:
- ✅ 使用简单(最低4行配置搞定聚合),学习成本低
- ✅ 解耦Spring Cloud Gateway网关组件,聚焦文档聚合功能,职责单一
- ✅ 提供手动配置、微服务自动发现两种灵活配置方式聚合子服务文档
- ✅ 可以同时聚合Swagger2、OpenAPI3两种不同的规范
- ✅ 灵活配置聚合规则,自定义排除规则支持
- ✅ 微服务场景下支持服务的上线、下线场景,文档状态与子服务保持一致,无需重启服务
🌚 3.深入了解
我们结合knife4j-gateway组件的特点来深入分析,带着疑惑来一步步揭开她的神秘面纱~!
✅ 3.1 使用简单(最低4行配置搞定聚合),学习成本低
首先,我们既然都已经封装成组件了,那么学习和使用成本是我们首先就需要考虑的事情,需要把复杂,难处理的业务逻辑、技术细节,全部封装在组件里,而对于上层用户,我们提供简化后的配置,开发者只需要开箱即用即可
这是组件的价值,剩下学习时间成本。
当然我说使用简单(最低4行配置搞定聚合),这只是有点宣传吹牛的口吻,对于开发者来说,我又要学习了解你这个knife4j-gateway组件的四行配置,那也是学习成本啊
这个我无从反驳~~~😂
如果开发者的项目、产品采用Spring Cloud微服务体系,网关组件使用Spring Cloud Gateway,那么对于Swagger、OpenAPI3的文档聚合,采用knife4j-gateway组件的话,就可以使用组件的discover自动发现模式,实现自动聚合
在项目中的application.yml配置文件中进行如下配置,就搞定了,配置如下:
knife4j:
gateway:
# ① 第一个配置,开启gateway聚合组件
enabled: true
# ② 第二行配置,设置聚合模式采用discover服务发现的模式
strategy: discover
discover:
# ③ 第三行配置,开启discover模式
enabled: true
# ④ 第四行配置,聚合子服务全部为Swagger2规范的文档
version: swagger2
我们没有使用广告法禁止的最简单、非常简单等宣传口吻进行宣传
摸着良心去看这个配置,用disocver模式进行聚合,四行配置达到开发者的目的,确实很方便啊,学习成本低~~~!
✅ 3.2 解耦Spring Cloud Gateway网关组件,聚焦文档聚合功能,职责单一
为什么我说解耦呢?因为文档功能其实是一个开发阶段的需求,是开发团队在配合完成项目、产品过程中,团队之前提升效率的一个潜在的需求场景
当我们的项目、产品开发完成,上线到生产环境的时候,或者在不同的项目开发过程中,开发者的需求又涌现出来了,例如:
- 接口规范是非常重要的内部信息,生产环境应该屏蔽
- 聚合代码在不同的项目中来回Copy
- 升级Gateway组件导致聚合代码失效,调试不同的Gateway版本,在线搜索解决方案
- ….
还有一些其他的需求场景,一线开发者可以自行脑补,上面说列的需求,你是否在开发场景中也碰到了呢?
既然文档聚合功能和项目、产品本身并没有太大的关系,是开发者开发过程中提高效率的产物,那么对于统一的事情,我们应该避免重复操作,用独立的中间件来解决这些问题
knife4j-gateway组件聚焦Swagger2/OpenAPI3规范的文档聚合,一旦团队之间确定使用Swagger2/OpenAPI3规范,并且有聚合的需求场景,那么引入一个jar组件就能解决的事情,何乐而不为呢?
✅ 3.3 提供手动配置、微服务自动发现两种灵活配置方式聚合子服务文档
上面我们从学习成本、解耦两个方面阐述了该组件的价值,那么接下来,当我们深入去探索网关组件的下的聚合场景时,站在中间件组件的立场下,我们就需要考虑不同的团队、不同的人员的需求进行兼容合并
目前为之,结合开发任何及自身的实际工作经验,总结出了两种文档聚合的场景,供开发者进行使用
- 手动配置聚合(manual): 开发者手动配置,灵活配置展示文档
- 优点:使用简单、灵活,学习成本低.试错成本低
- 缺点:服务众多时较繁琐,无法感知子服务的上下线状态
- 服务发现自动聚合(discover):基于注册中心,主动聚合服务
- 优点:使用及配置简单、学习成本低.
- 缺点:暂时没想到,欢迎你来体验反馈
✅ 3.4 可以同时聚合Swagger2、OpenAPI3两种不同的规范
我们的项目/产品在长期迭代开发过程中,或者不同的团队配合开发中,有时候子服务的标准可能不尽统一。而我们需要一起聚合怎么办呢?
好在在Knife4j的前端Ui组件已经完全适配了Swagger2和OpenAPI3规范,在网关层面,我们只需要根据该组件提供的手动配置策略配置上就解决了该问题,可参考下面的文章介绍。
✅ 3.5 灵活配置聚合规则,自定义排除规则支持
灵活配置是knife4j-gateway组件为网关聚合服务提供的带刀侍卫,保障开发者们在手动/服务发现两大场景下配合使用以达到最终目的
他主要提供的服务包括:
- 设定网关层面聚合的排除规则,支持正则表达式或者开发者根据SPI接口自定义实现
例如有Dubbo服务的接口,需要在网关层面进行排除,禁止聚合
- 子服务的服务名称别名、展示顺序、接口顺序等配置自定义
- 子服务的自定义ContextPath自由灵活配置,满足业务需要
1、在网关层面,排除不需要的子服务时,我们可以基于正则表达式(自4.3.0版本进行支持),配置如下:
knife4j:
gateway:
enabled: true
strategy: discover
discover:
version: swagger2
enabled: true
# 排除不需要聚合的子服务,基于正则表达式(支持多个)
excluded-services:
# 排除order开头的服务
- order.*
# 排除服务中包含dubbo字样的服务
- .*?dubbo.*
2、配置子服务的别名,排序,自定义配置如下:
knife4j:
gateway:
enabled: true
strategy: discover
discover:
version: swagger2
enabled: true
excluded-services:
- order.*
# 自定义配置子服务的别名,排序规则
service-config:
order-service:
- group-name: 订单服务
order: 1
user-service:
- group-name: 用户服务
order: 2
3、网关成统一开启配置子服务的tag、operation排序规则
knife4j:
gateway:
enabled: true
strategy: discover
discover:
version: swagger2
enabled: true
# 排序规则
tags-sorter: order
operations-sorter: order
🐐 4.聚焦两大使用场景(手动/服务发现自动)聚合
4.1 手动配置聚合(manual)
手动配置聚合,顾名思义,开发者需要自行写子服务的规则或者路径,这和微服务场景下自动复现聚合是形成互补机制,双剑合璧威力之下,完成最终成果输出
该场景解决不同的问题,包括:
- 子服务同时存在Swagger2/OpenAPI3规范的服务
- 子服务存在不同的package包分组的的规范实例,用过springfox或者springdoc的开发者应该清楚可以根据package包路径、path路由创建接口分组
如下图:
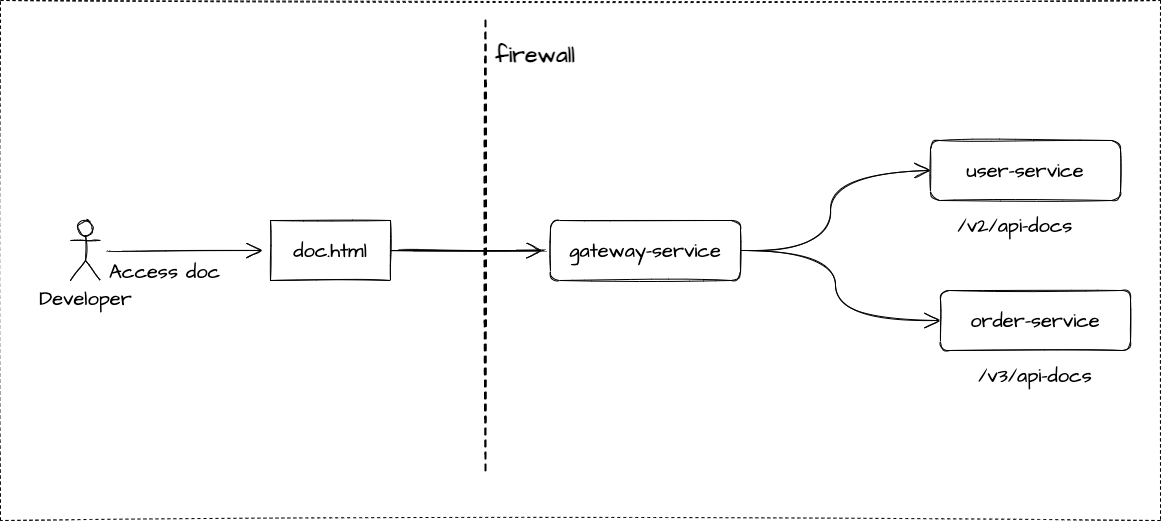
这是一个简单的示意图,我们有三个服务:
- gateway-service:网关服务,负责网关路由鉴权、路由转发
- order-service:子服务之一,基于OpenAPI3规范暴露规范地址:
/v3/api-docs - user-service: 子服务之一,基于Swagger2规范暴露规范地址:
/v2/api-docs
我们从服务架构流程图中了解到了我们需要的信息,那么在gateway-service组件中,就可以使用knife4j-gateway组件提供的手动配置聚合,将文档进行聚合展示
简单的配置如下:
knife4j:
gateway:
enabled: true
# 选择手动
strategy: manual
routes:
- name: 用户服务
service-name: user-service
url: /user/v2/api-docs
- name: 订单服务
service-name: order-service
url: /order/v3/api-docs
4.2 服务发现自动聚合(discover)
手动聚合的唯一问题就是,一旦我们的产品/项目,子服务数量众多,纯靠手动去配,那对于开发者来说也是极其痛苦的,就好像是侮辱开发者一样。。
我都能写代码了,你还让我写这么多繁杂的配置,那是对程序员的不尊重。
基于服务发现自动聚合的需求场景,就由此诞生.
在上面我们介绍knife4j-gateway特点时,我们提到该组件解耦,聚焦文档聚合功能,职责单一,这里得以体现
对于服务发现场景下的自动聚合,配置就更简单了,但对我们也有一些小小的约束
⚠️ 我们的子服务规范实现需要统一,要么全部用Swagger2规范,或者OpenAPI3规范
配置如下:
knife4j:
gateway:
# ① 第一个配置,开启gateway聚合组件
enabled: true
# ② 第二行配置,设置聚合模式采用discover服务发现的模式
strategy: discover
discover:
# ③ 第三行配置,开启discover模式
enabled: true
# ④ 第四行配置,聚合子服务全部为Swagger2规范的文档
version: swagger2
这个特点和我们前面提到的使用简答这一条又对上了,真的只有三四行配置。
但是在微服务聚合场景下,我们虽然封装内部实现,也有必要和大家分享一下,具体的处理规则原理
先来看一张简单的架构图-服务发现的场景,如下图:
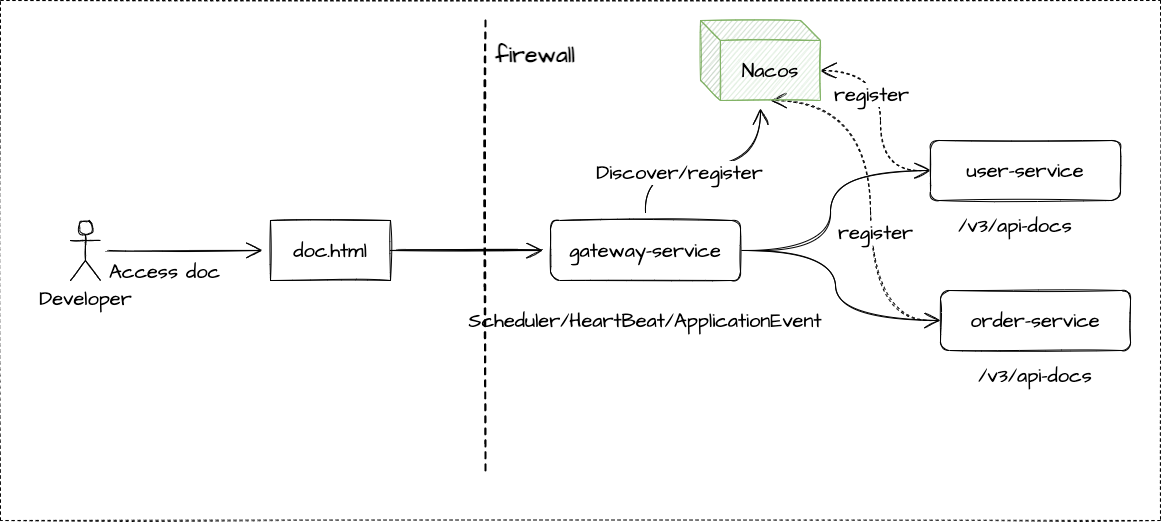
在服务发现的场景中,我们依赖注册中心组件,这里以Nacos为例,但我们将网关服务gateway-service也注册到Nacos中时
本身基于Spring Cloud微服务体系的DiscoverClient.java接口,在Nacos组件实例下,会为我们解决各个子服务注册上来的服务发现问题,包括子服务实例对象,是否上线、心跳检测等等
而我们依赖Spring体系提供的ApplicationEvent事件监听体系,就可以从统一的DiscoverClient体系下,实现我们的自动聚合场景,这样的好处是不用关心各个注册中心的差异,在Spring Cloud的微服务体系下,注册中心需要遵循DiscoverClient接口进行标准实现。
在knife4j-gateway的服务发现场景下,我们通过@EventListener实现对微服务场景下的事件监听,以填充网关成文档的数据实现
监听事件回调处理源码如下:
@Slf4j
@AllArgsConstructor
public class ServiceChangeListener {
final DiscoveryClient discoveryClient;
final ServiceDiscoverHandler serviceDiscoverHandler;
final Knife4jGatewayProperties knife4jGatewayProperties;
@EventListener(classes = {ApplicationReadyEvent.class, HeartbeatEvent.class, RefreshRoutesEvent.class})
public void discover() {
log.debug("discover service.");
List<String> services = discoveryClient.getServices();
if (Objects.equals(knife4jGatewayProperties.getStrategy(), GatewayStrategy.DISCOVER)) {
this.serviceDiscoverHandler.discover(services);
}
}
}
通过注册中心在DiscoverClient体系下的实现,包括调度(Scheduler)、心跳检测(HeartBeat)、事件回调(ApplicationEvent)等机制,实现微服务网关层面文档的自动聚合。
🐮 5.服务发现的路由聚合策略-数据来源
在上面章节中,我们从使用特点、两大场景(手动/服务发现)等全面介绍了knife4j-gateway组件,在文末,还是有必要和大家讲讲该组件在discover服务发现模式下,子服务的是数据来源处理规则
主要是4个方面,包括:
- 基于Spring Cloud Gateway配置的routes规则解析子服务路由,数据来源:
spring.cloud.gateway.routes - 在discover服务发现场景下,针对自定义添加的routes,默认再次追加,数据来源:
knife4j.gateway.routes - 服务发现discover模式下,开发者在网关成的路由转发模式默认通过DiscoveryClient的默认方式转发路由,规则是
pattern:/service-id/** - 接收编码方式动态注入Spring Cloud Gateway网关的路由,进行聚合转发
5.1 手动配置-自定义Routes
自定义Routes主要是开发者根据Knife4j-gateway组件提供的开发配置,在进行手动聚合时,填写的配置,这部分的配置是网关聚合的数据来源之一
而配置内容knife4j-gateway组件不会做任何处理,开发者配置什么就展示什么
示例配置如下:
knife4j:
gateway:
enabled: true
# 选择手动
strategy: manual
routes:
- name: 用户服务
service-name: user-service
url: /user/v2/api-docs
5.2 DiscoverClient自动发现
如果开发者在Spring Cloud Gateway网关组件下没有配置子服务的转发路由规则,完全依靠默认的转发规则(pattern:/service-id/**),其实就是根据子服务名称进行转发
在这种规则下,knife4j-gateway组件会读取DiscoverClient组件下注入的DiscoveryClientRouteDefinitionLocator路由列表进行解析
在Spring Cloud Gateway网关的配置,开启该规则,配置如下:
spring:
# 路由网关配置
gateway:
# 启用了自动根据服务名建立路由
discovery:
locator:
enabled: true
lower-case-service-id: true
而knife4j-gateway组件中,就是直接获取该模式下的子服务列表转发规则,注入到knife4j-gateway组件下的数据源,作为ui层面的转发依据
部分源码解析如下:
public class DiscoverClientRouteServiceConvert extends AbstactServiceRouterConvert {
final DiscoveryClientRouteDefinitionLocator discoveryClientRouteDefinitionLocator;
final Knife4jGatewayProperties knife4jGatewayProperties;
@Override
public void process(ServiceRouterHolder holder) {
log.debug("Spring Cloud Gateway DiscoverClient process.");
// 取默认子服务的路径规则
discoveryClientRouteDefinitionLocator.getRouteDefinitions()
.filter(routeDefinition -> ServiceUtils.startLoadBalance(routeDefinition.getUri()))
.filter(routeDefinition -> ServiceUtils.includeService(routeDefinition.getUri(), holder.getService(), holder.getExcludeService()))
.subscribe(routeDefinition -> parseRouteDefinition(holder, this.knife4jGatewayProperties.getDiscover(), routeDefinition.getPredicates(), routeDefinition.getUri().getHost(),
routeDefinition.getUri().getHost()));
}
//others...
}
5.3 Spring Gateway网关Routes配置
该配置属性和自定义配置knife4j-gateway组件的routes一样,开发者一般会自定义配置子服务的路由转发策略,通过spring.cloud.gateway.routes进行配置
而knife4j-gateway会获取该部分的数据源,通过读取子服务配置的Predicate来获取子服务的Path前缀ContextPath规则进行聚合
5.4 动态路由注册配置
动态路由注册可能在某些特殊的场景下也有需求,因此knife4j-gateway也会把动态注入进来的路由进行聚合,作为文档数据源进行展示
动态数据源来源于RouteDefinitionRepository对象
6.👻 总结
好了,本文介绍到这里也基本涵盖了knife4j-gateway网关聚合组件的方方面面,希望该组件能给你带来帮助~~!
您有更多的想法或者建议,可以关注公众号”八一菜刀”,参与Knife4j的交流群进行沟通反馈,谢谢

