写在前面
首先,非常感谢关注Knife4j项目的朋友,该公众号应该是今年开始,对于开源项目Knife4j的更新都在此公众号进行了第一时间的发布更新,包括该项目的迭代、想法、实践等等内容,包括最近Knife4j的付费产品Knife4jInsight的推出,虽然更新的不是很频繁,但对于还是要给自己一直坚持的事情做输出点赞的(感动了自己😹)。对于写公众号而言,对于文章的发表,如果有人持续关注的话,会是一种正向的鼓励~!
而现在,考虑到我实际工作中的内容,目前工作核心是在做大模型RAG(检索增强生成)方面的开发工作,主要还是以Java技术栈进行产品的功能迭代开发,Python语言则更多的偏向底层大模型方面,包括大模型(LLM)的训练、微调、数据标注、向量Embedding等领域,工程上,业务产品测的逻辑实现、编排,接口开发等等功能还是以Java语言实现为主,并非使用当下最火的LangChain、LlaMaIndex等Python框架,我在昨天看一本书**《Java开发之道》**里面提到,开发者在实际开发过程中,在产品或项目开发周期结束后,需要善于总结自己的工作内容,我觉得以Blog或者视频的形式进行输出最好,这样才能更快速的成长。
我回想起这么多年的工作,对于一个领域,不管是技术层面,或者是业务层面,似乎一直是缺少总结性的输出的,或者说做的都不是太深入。在早些时候,我和我的老大哥员外说,这么多年做的东西不管是产品、还是项目,都不太能拿的出手,而随着时间越久,这种深深的挫败感就从内心油然而生,每每想起,都自感恼火😫。主要原因还是我们做的东西都太表面了,在技术层面,我们很多技术都是浮于表面,并没有做持续深度的精进,产品层面,一个像样的产品是经过千锤百炼的打磨的,细扣每一个细节,把同类竞品比下去,也许产品上面一个看似不起眼的优点,都能把同类的竞品给比下去,而要做到产品上的优势体现,技术人员的投入是成正相关的。项目就更不用说了,**交钥匙工程(内部代号,意指项目做完就验收了,至于使用如何,功能好不好用从来没care过,业主也不care)**的项目做的已经数都数不过来了。
而最近我和我的老伙计员外已经一头扎进了AI大模型、RAG(Retrieval Augmented Generation-检索增强生成)这个赛道,每天讨论的都是大模型、RAG等相关内容,然后产品的技术栈开发又是Java为主,Python为辅,在Java语言这个领域开发AI应用,好像目前在RAG这个领域并没有相关的技术文档、博客输出,基本80%都是Python,我在看了LangChain、LlaMaIndex等Python框架处理开发大模型应用(主要是RAG)时,除了在本地加载大模型外,很多其实都是工程方面的知识,并非一定要使用Python语言来进行开发,而我最近实际工作中又在做这个,因此,希望能够通过以Java+Python两种语言的形式,通过学习大模型、RAG等新型领域的知识,甚至是学习Python语言,将自己学到的内容以及一些工作中的实践通过文章的方式进行输出分享,更多的还是会将内容应用的实际的产品中,也希望在这个领域做一个深耕,不管是技术上还是业务领域,大模型这一波,我觉得每一个开发者都应该持续保持关注。
在AI大模型、RAG这个赛道,我们要做的事情:
-
技术:深挖AI大模型、RAG领域的技术细节(应用工程领域),从思想、代码、架构等领域都需要花120%的投入,知其所以然!
☑️ 考虑到我并非搞算法的人员,底层的大模型算法等内容,我觉得对于我自己的要求而言,做到知道、了解即可,甚至有必要的话,搞一张4090(太贵了,还没舍得买)的卡跑跑预训练的模型也是有必要的!
☑️ RAG领域在工程层面的知识所涉及的面也是足够广的,对于做应用开发者而言,也并非一朝一夕就能全盘了解其中的细节,需要做的就是两字:“深耕”
☑️ 技术层面有时候是需要较真一下的,解决关键的核心技术问题是对竞对产品的致命打击
-
产品:坚持价值输出导向,倾听客户的意见,坚决反对交钥匙工程
☑️ 技术上输出最终都会落地到实际应用产品的开发上,而产品需要坚持的事情则是要尊重用户,技术测则需要尊重产品
☑️ 价值输出导向是永恒的真理,客户付费买单,最终看中的也是这个产品所带来的价值,或者说能够给客户带来收益(赚钱才是硬道理)
☑️ 做顺势而为的事情,而大模型这一波技术浪潮,我觉得做这方面相关的内容或者产品技术探索,就是顺势了
🆕 新名称
这个公众号之前都是以Swagger/OpenAPI/Knife4j等领域相关的名称,因为一直在维护开源项目Knife4j,主要还是和接口相关的,就一直用了这些名称!思来想去,公众号的性质也是个人性质,以后更多的还是以个人的一些想法、工作实践等内容为主进行输出,就干脆换回之前一直用的网络昵称名称吧:八一菜刀
🆕 名称含义(该公众号之前注册时也是用的这个名称,相当于恢复出厂设置了)
八一:字面意思一致
菜刀:作者故乡来自湖南省桑植县,贺龙元帅故乡,贺老总两把菜刀闹革命是旗帜,以此纪念,同时也有时刻思念故乡之意!
✍️ 要写一些什么呢?
目前看来,主要两个方面:
- 开源:开源项目Knife4j并没有停更,所以和这个项目相关的内容、资讯等,也会同步发布在这个公众号里面,这个项目作者有精力的情况下还是会持续更新下去的。
- RAG:以学习者的心态,学习大模型领域相关的技术,特别是RAG领域,这块领域我觉得哪怕你不是一个算法人员,而仅仅只是一个普通的开发者(Java/Python/.Net等),是可以触控可及的,而我的工作中目前正在做这类产品的开发迭代,不管是学习或者工作中,必然会碰到很多棘手的问题,那么就会将自己的思考以及实践总结分享出来。
结合我最近的工作内容,我总结了一部分的大纲内容(后面随着学习的深入可能会扩展更多),如下图:
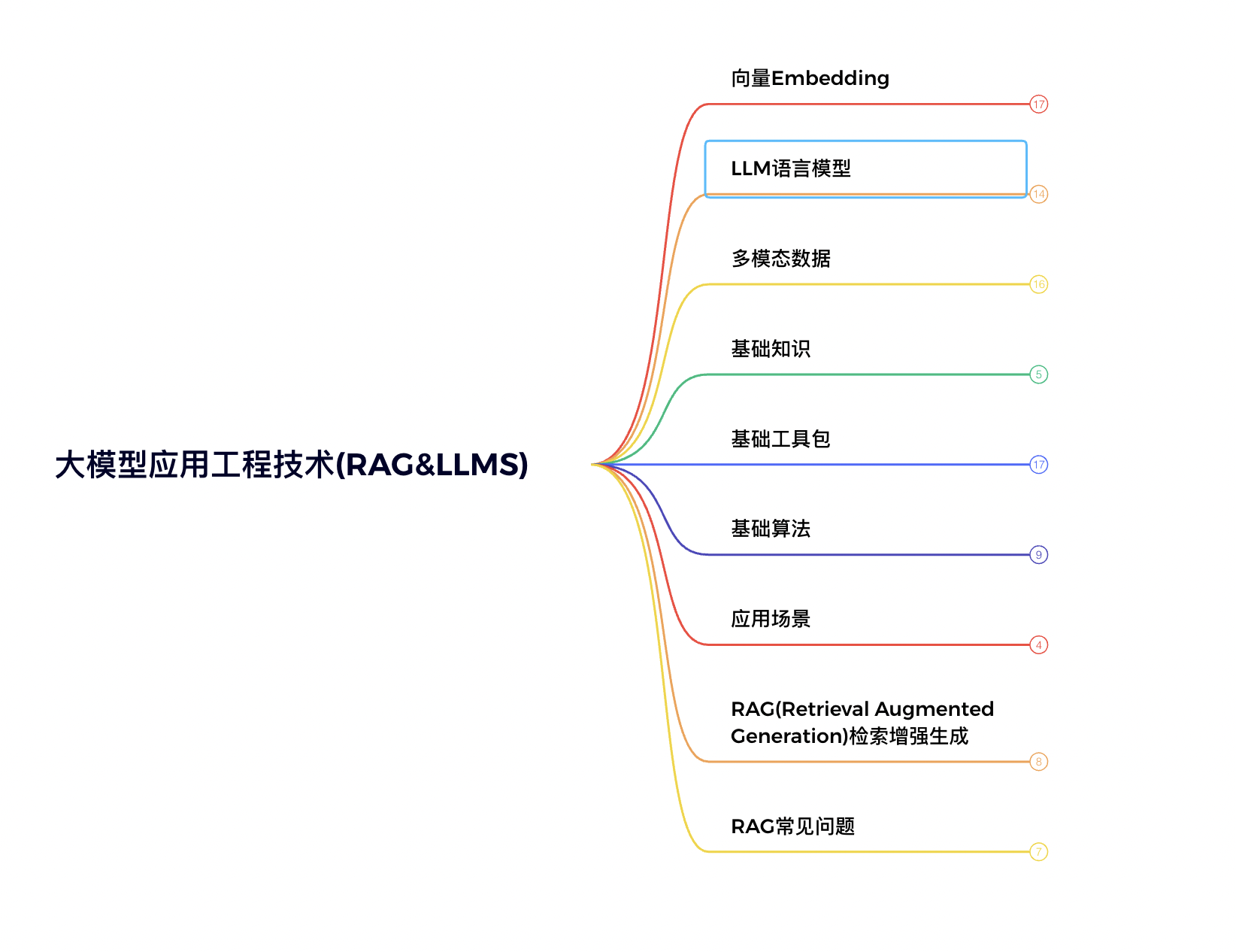
在技术层面,我愿称这方面的技术合集为”大模型应用工程技术”。
为什么这么说呢?主要几个方面:
- 主要还是基于应用层面的技术围绕展开,而底层的大模型训练、数据标注、**基于预训练模型的微调(Fine-turn)**等领域,我觉得那是专业算法人员干的事情,比如基于企业的私有数据调整开源预训练大模型的权重,通过SFT手段进行微调,或者从0到1基于数据语料构建一个全新的垂直领域的Embedding模型,这已经属于更便底层的领域了,相信很多和我一样的Java开发人员其实像接触到这方面的知识,哪怕是学习都是很吃力的,就做到了解和知道吧,看个人兴趣。
- 而RAG领域的知识点,更多的是偏工程应用技术,包括数据的处理、存储、逻辑编排等等对于非算法领域的人员,对于业务开发人员来说我们是擅长的,虽然也是和AI大模型挂钩,但LLM作为底层的基础设施,我们更多的是使用大模型的能力,在大模型基础之上,构建上层的应用烟囱,所以作为开发人员,是可以尝试去学习、了解的,我认为是触手可及的。
而在”大模型应用工程技术”,我初步列了一个大纲(后面随着学习的深入可能会扩展更多)
目前包含的几个方面:
- 向量Embedding:在RAG领域中,将多模态数据(文本、图像、视频、音频等数据)进行向量Embedding的嵌入转化,通过向量计算召回Top k,可以解决很多实际生产中的问题,比如:文本相似度计算、以图搜图、以文搜图等等,这方面都会涉及到向量的知识。
- LLM语言模型:LLM大模型(Large Language Model)作为基础设施,是上层应用的基石,但是在应用领域中,对大模型的了解也是很有必要的,包括Prompt的构建优化、模型参数的差异以及不同效果体现、模型的部署和训练微调、开源模型以及商业模型等等
- 多模态数据:RAG相关的AI应用,离不开数据的处理,在很多LLM大模型中,也标注为多模态大模型,包括文生图、图生图等等,但在应用领域,文本(pdf/word/html/text等)、图片、视频、音频等等格式的数据处理是无可避免的,还包括市面上很多非结构化的数据处理等内容,工程层面的技术可以说是如星辰大海般辽阔,技术人员学习之路无穷无尽。
- **基础知识:**在做应用层面的开发上,当然离不开基础知识点的学习,常用的包括HTTP SSE协议、向量等等知识点。
- 基础工具包:工欲善其事,必先利其器,在当下的开源大环境下,有非常多的优秀的工具辅助开发者开发生产级别的应用,以Python、Java这两大语言生态为标杆,生态及其丰富,而我们在做应用成技术的开发离不开这些优秀的组件,掌握组件的用法也是必须的。
- **基础算法:**虽然是做应用层面的开发,基础的常用算法,该学习的还是需要去了解的,像贝叶斯、KNN、决策树等等,了解算法的原理实践,对于生产环境的代码编写时非常有指导思想的,否则你都不知道这段代码为何这么写,而每个算法解决的都是非常实际的问题。
- **应用场景:**技术人员在开发产品时,也应该关注应用场景及市场,开发出来的产品解决了什么问题,有什么价值作为技术人员也应该学会思考。在大模型领域,以RAG赛道来看,触及的场景其实也是非常多的,比如:智能客服、以图搜图/视频等等,要关注实际的产品需求,然后转化为技术输出,这样我们作为开发人员所写的代码才是有价值的。
- RAG:RAG全称Retrieval Augmented Generation(检索增强生成),是属于AI生成式技术领域范围,解决大模型的幻觉(胡说八道)、数据不及时(数据未更新)等领域的问题,通过将企业自己的数据通过传统的工程技术结合向量Embeding进行处理,然后通过检索的方式将企业内部数据构建送给大模型进行内容的回答生成,这种方式有效的避免了大模型胡说八道和数据不准确的问题,在企业不同的领域中有非常宽广的应用领域,当然这里面所涵盖的面以及问题也是非常的广,比如:
- 大模型出现幻觉(送给LLM的Context不准,导致大模型胡说八道)如何解决?
- 按固定size进行分割,出现上下文语义丢失,核心信息检索问答生成失败,回答不准确
- 千万级数据量文档检索效率问题
- 大模型Token限制问题导致在一个文档中出现多段落讲解同一个事情的情况下会回答不完整如何处理
- …
这些都只是AI大模型、RAG等领域的冰山一角,千里之行,始于足下,作为技术人员,那么就从现在开始,一步步学起来吧~
最后
如果你最近也在做RAG领域相关的技术研究或者产品开发,欢迎关注、沟通交流合作!!!