前言
在不久前苹果官方开源发布了针对Apple Silicon 芯片优化的 MLX 深度学习框架,该框架可以简化研究人员在 Mac、iPad、iPhone 平台设计和部署模型的过程。
MLX的主要特性包括:
- 熟悉的API:MLX 具有紧随 NumPy 的 Python API。 MLX 还拥有功能齐全的 C++ API,它与 Python API 非常相似。 MLX 具有
mlx.nn和mlx.optimizers等更高级别的包,其 API 紧密遵循 PyTorch,以简化构建更复杂的模型。 - 可组合函数转换:MLX 具有用于自动微分、自动矢量化和计算图优化的可组合函数转换
- 惰性计算 (Lazy computation):MLX 中的计算是惰性计算。数组仅在需要时才会具体化
- 动态图构建:MLX 中的计算图采用动态构建,更改函数参数的形状不会触发缓慢的编译,并且调试简单直观
- 多设备:可以在任何支持的设备上运行(当前为 CPU 和 GPU),确保用户能够充分利用硬件
- 具备统一内存优势:MLX 和其他框架的显着区别是采用统一内存模型。 MLX 中的数组位于共享内存中,可以在任何支持的设备类型上执行 MLX 阵列上的操作,而无需移动数据。
项目地址:https://github.com/ml-explore/mlx
而在今天的X上看到Apple开发者分享说可以在32GB的M1设备上使用MLX框架对Mistral 7B(或者llamA)等模型进行微调(Fine-tune)
准备
看到官方的例子,我的电脑正好是M1 32GB的配置,就把代码跑来试试看
首先代码下载下来,地址:https://github.com/ml-explore/mlx-examples/tree/main/lora
安装依赖:
pip install -r requirements.txt
下载Mistral-7B(14.48GB大小)的模型并解压
curl -O https://files.mistral-7b-v0-1.mistral.ai/mistral-7B-v0.1.tar
tar -xf mistral-7B-v0.1.tar
将下载下来的模型文件进行转换,执行convert.py文件, 命令如下:
# 转换命令
python convert.py \
--torch-model <path_to_torch_model> \
--mlx-model <path_to_mlx_model>
# 转换
python convert.py \
--torch-model mistral-7B-v0.1 \
--mlx-model mistral-7b-v0.1-mlx
两个主要的参数:
- torch-model: Mistral模型的目录,解压后为当前的
mistral-7B-v0.1 - mlx-model: 输出目录名称,这里取名
mistral-7b-v0.1-mlx
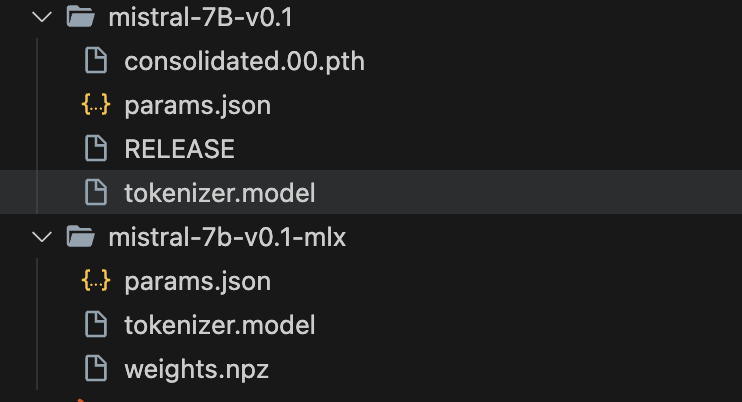
通过命令转换后,转换的目录文件会有三个文件,如下图:
微调(Fine-tune)
将模型下载转换完成后,接下来就可以使用官方提供的lora.py进行微调(Fine-tune)了,先来看数据集:
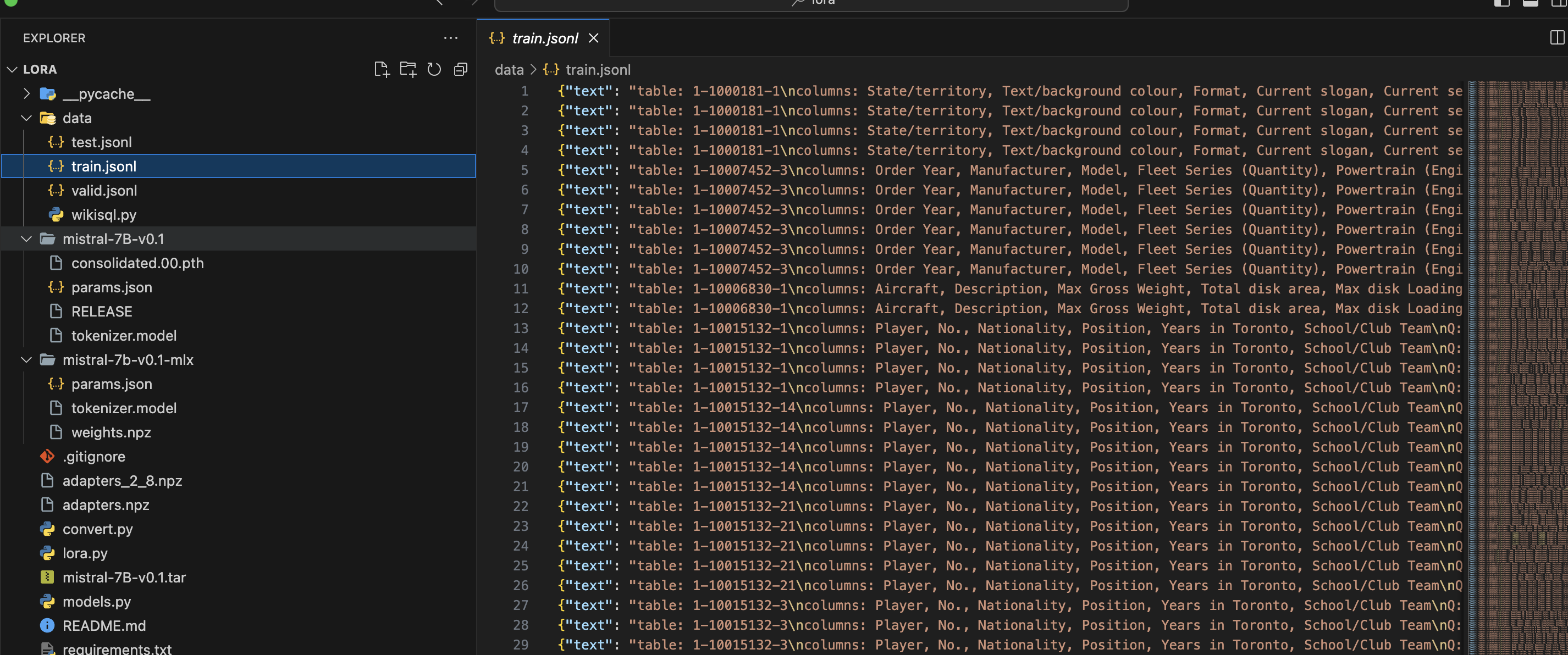
训练的数据集是1000行,主要的格式:
微调目标是得到一个能够将自然语言句子转换为SQL
{
"text": "table: 1-1000181-1\ncolumns: State/territory, Text/background colour, Format, Current slogan, Current series, Notes\nQ: Tell me what the notes are for South Australia \nA: SELECT Notes FROM 1-1000181-1 WHERE Current slogan = 'SOUTH AUSTRALIA'"
}
数据集的格式很清晰:
table: 表名称
columns: 列名称
Q: 用户问题
A: SQL语句
训练
在第一次train的过程中,直接使用demo中的命令:
python lora.py --model <path_to_model> \
--train \
--iters 600
运行了大概10分钟后,程序就异常退出了,提示内存不足。
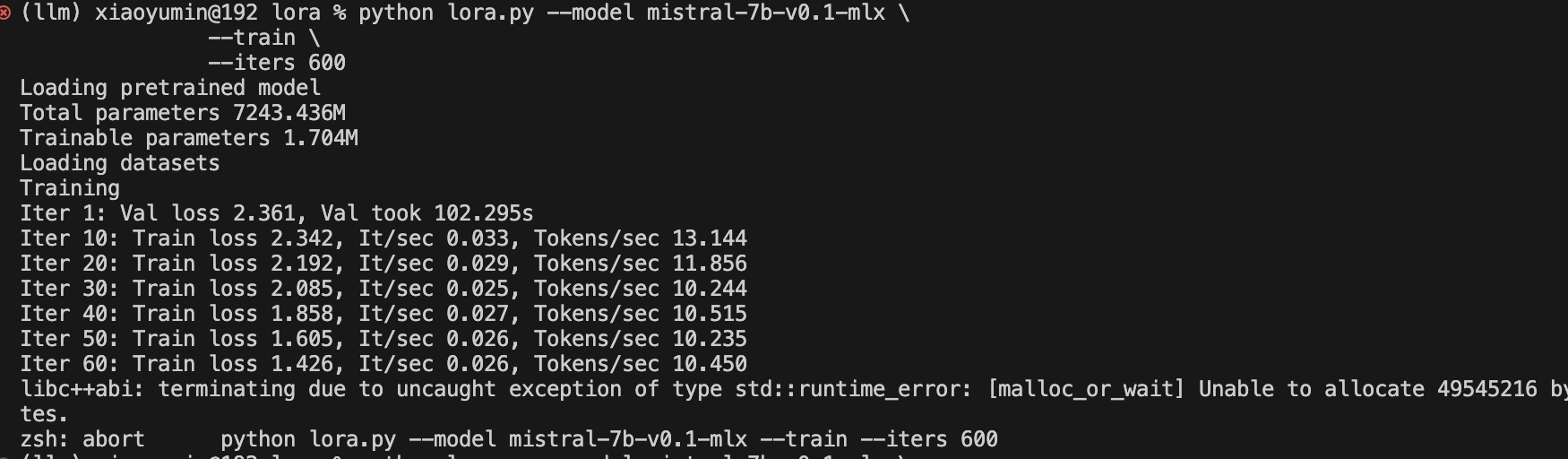
从图中可以看出,在声明内存的过程中,出现了异常,无法开辟新内存空间,并且每秒的Tokens数量也很感人😭
在看了官方的针对内存的issues建议后,发现有几个参数是影响着内存使用的:
- –batch-size:尝试通过
--batch-size使用较小的批量大小。 默认值为 4,因此将其设置为 2 或 1 将减少内存消耗。 这可能会减慢速度,但也会减少内存使用。 - –lora-layers:少层数以使用
--lora-layers进行微调。 默认值为 16,因此您可以尝试 8 或 4。这会减少反向传播所需的内存量。 如果您使用大量数据进行微调,它还可能会降低微调模型的质量。 - 数据集:较长的示例需要更多的内存。 如果这对您的数据有意义,您可以做的一件事是在制作 {train, valid, test}.jsonl 文件时将示例分解为更小的序列。
根据官方的建议,那么修改train参数,如下:
python lora.py \
--model mistral-7b-v0.1-mlx \
--train \
--batch-size 1 \
--lora-layers 4
按这个命令执行后,在我的M1设备上执行的还比较快,每秒的Tokens数量平均上110左右
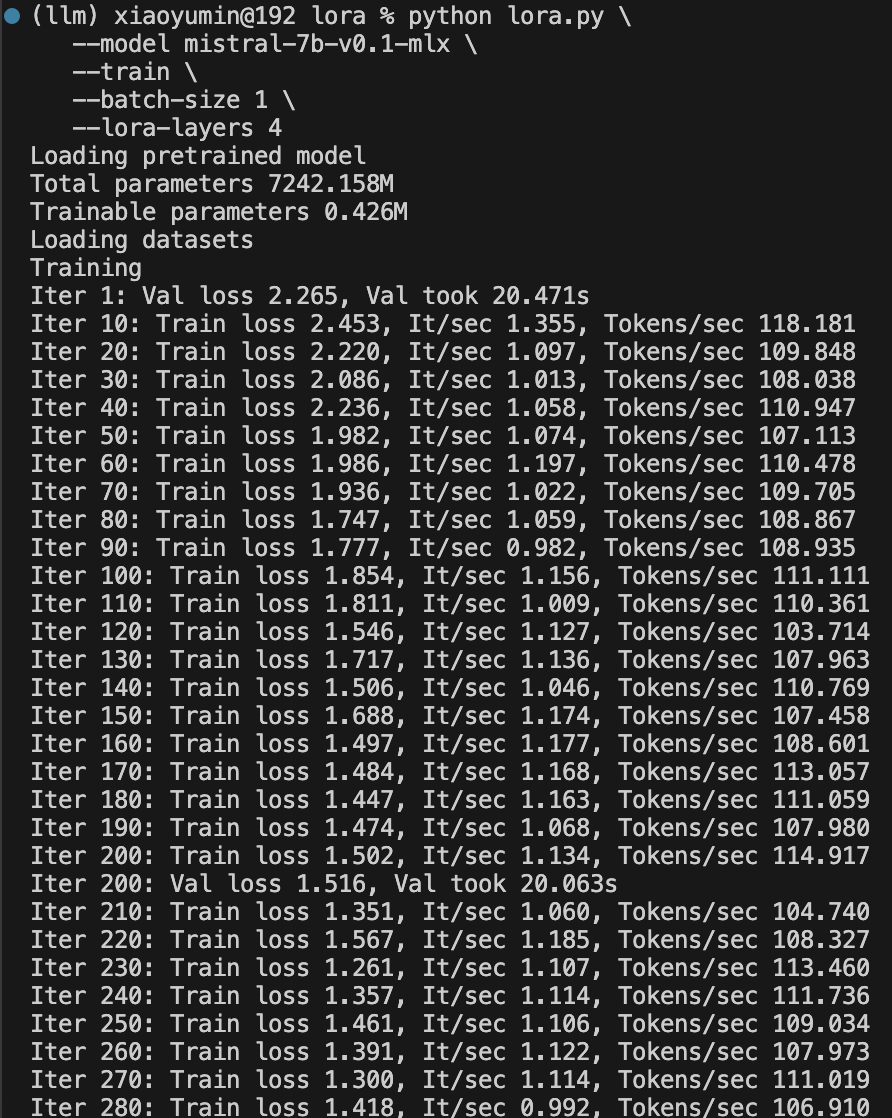
而Loss的值如下:
| Iter | Loss |
|---|---|
| 1 | 2.265 |
| 200 | 1.516 |
| 400 | 1.380 |
| 600 | 1.350 |
| 800 | 1.325 |
train完成后,会在本地默认生成一个权重文件adapters.npz
测试结果:
python lora.py --model mistral-7b-v0.1-mlx \
--adapter-file adapters.npz \
--num-tokens 50 \
--prompt "table: 1-10015132-16
columns: Player, No., Nationality, Position, Years in Toronto, School/Club Team
Q: What is terrence ross' nationality
A: "
Loading pretrained model
Total parameters 7243.436M
Trainable parameters 1.704M
Loading datasets
Generating
table: 1-10015132-16
columns: Player, No., Nationality, Position, Years in Toronto, School/Club Team
Q: What is terrence ross' nationality
# 大模型输出
A: SELECT Nationality FROM 1-10015132-16 WHERE Player = 'Terrence Ross' blowing off the rosshill. SELECT Nationality FROM 1-10015
从结果看,SQL的前半部分写对了,并且也识别出了字段、where条件,但是后面的句子好像就不太对了
我怀疑是在train时,参数--lora-layers 4的问题,这时,我将改参数改为8,在train一次
python lora.py \
--model mistral-7b-v0.1-mlx \
--train \
--adapter-file adapters_2_8_1.npz \
--batch-size 2 \
--lora-layers 8
而Loss的值如下:
| Iter | loss |
|---|---|
| 1 | 2.348 |
| 200 | 1.392 |
| 400 | 1.293 |
| 800 | 1.213 |
| 1000 | 1.233 |
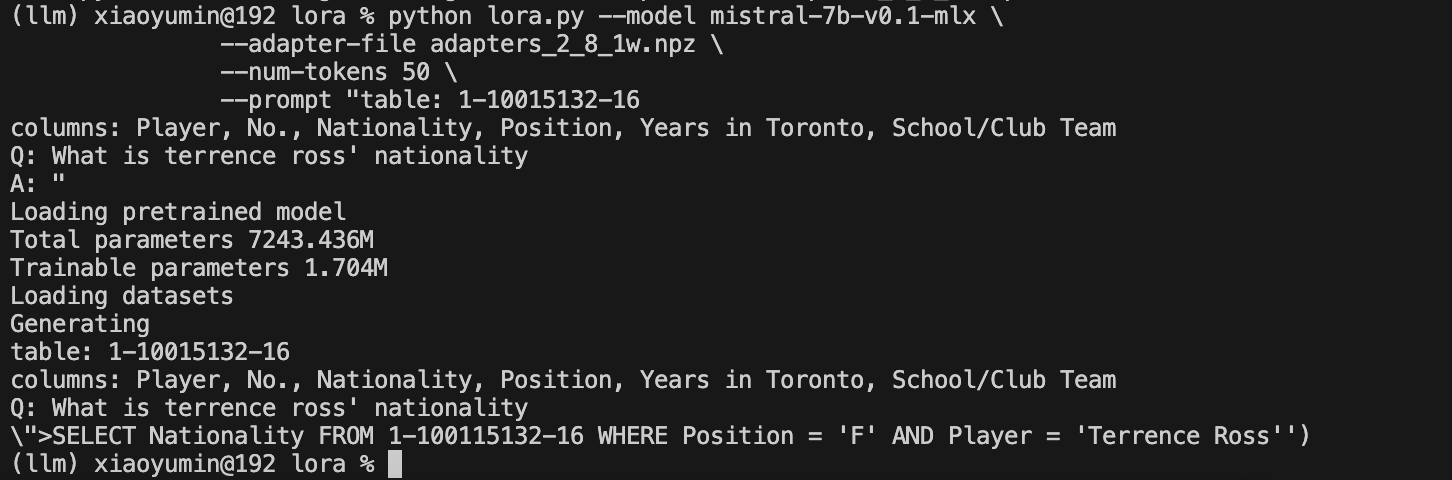
之后,同样的命令,再来看效果:
python lora.py --model mistral-7b-v0.1-mlx \
--adapter-file adapters_2_8.npz \
--num-tokens 50 \
--prompt "table: 1-10015132-16
columns: Player, No., Nationality, Position, Years in Toronto, School/Club Team
Q: What is terrence ross' nationality
A: "
Loading pretrained model
Total parameters 7243.436M
Trainable parameters 1.704M
Loading datasets
Generating
table: 1-10015132-16
columns: Player, No., Nationality, Position, Years in Toronto, School/Club Team
Q: What is terrence ross' nationality
A: SELECT Nationality FROM 1-10015132-16 WHERE Player = 'Terrence Ross' SELECT Nationality FROM 1-10015132-16 WHERE
看效果好像在SQL语句中,比上面的效果稍微要好一点了?但是结果还是不对。
效果并没有达到预期,我觉得主要是可能有几个方面的原因:
- 训练数据集太少,导致大模型可能无法,train.jsonl中的数据集是1000
- 参数
--lora-layers的问题,默认是16,虽然我最后改成了8,但是从官方给出的说明来看,该参数会影响质量
我将参数--lora-layers 修改为16进行了尝试,跑不了,可能还是我的内存太低了😭,那我只能加数据集了
修改了data目录下的wikisql.py文件,将数据集下载整理的总体数量上升到10000,代码:
if __name__ == "__main__":
datanames = ["train", "dev", "test"]
sizes = [56355, 8421, 15878]
for dataname, size in zip(datanames, sizes):
len(WikiSQL(dataname)) == size, f"Wrong {dataname} set size."
# Write the sets to jsonl
import json
train, dev, test = load()
# 此处原train参数是1000,我改成5000
datasets = [
(train, "train", 10000),
(dev, "valid", 1000),
(test, "test", 1000),
]
for dataset, name, size in datasets:
with open(f"data/{name}.jsonl", "w") as fid:
for e, t in zip(range(size), dataset):
# Strip the <s>, </s> since the tokenizer adds them
json.dump({"text": t[3:-4]}, fid)
fid.write("\n")
修改数据集后,在train过后,得到一个新的权重文件,命令:
python lora.py \
--model mistral-7b-v0.1-mlx \
--train \
--adapter-file adapters_2_8_1.npz \
--batch-size 2 \
--lora-layers 8
loss的train过程分值变化:
| Iter | loss |
|---|---|
| 1 | 2.348 |
| 200 | 1.472 |
| 400 | 1.410 |
| 600 | 1.387 |
| 800 | 1.360 |
| 1000 | 1.349 |
再来看看我们的promt得到的结果:
从结果来看,SQL语句的语法好像并没有什么大的问题,只是结果没有达到预期,可能还是得从数据集及相关参数找一下原因。
结论
虽然运行的结果还没有完全达到预期,但是在MAC上通过Apple推出的MLX深度学习框架进行Fine-ture的技术方案是可行的。
这也为以后大模型的训练、生态发展提供了另外一种可能性。
包括我们应用开发者在做RAG的过程中,和数据进行对话的场景随着业务的深入肯定会触及,而对模型进行微调是不可避免的。

